iRe-VLA#
Paper ↗
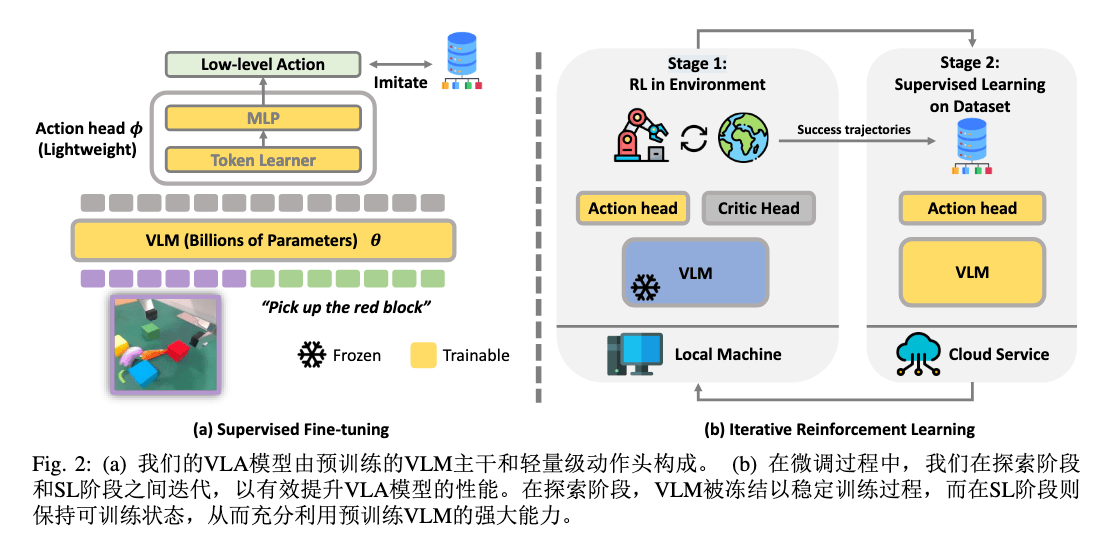
Insight#
- RL 只用以更新少部分参数,即 Action 头,从而避免 RL 大规模更新参数的不稳定。
- SFT 来更新 LLM,更加稳定
- 训练过程:先 SFT,然后迭代进行 RL(PPO,on-policy)和 SFT
Intresting#
- LLM 用以高层规划(分解任务,无法直接应用于物理世界)或者低层控制信号(LLM 中引入 Action Token 或者后接动作头)
- RL 直接用以提升 VLA 输出的低层控制信号
- RL 得到的新成功轨迹加入数据集,on-policy
- RL 用以探索,SFT 用以记忆
Arch#
Backbone:BLIP
Componentes:LoRA,TokenLearner(压缩多 token 到单 token)
Reward Signal:MSE (SFT), 01 Sparse (RL)
Result#
当在线数据 ∣DRL∣>0.3∣De∣ 时,超越纯模仿学习的涌现能力(应对遮挡、动态干扰)。
RLPD#
Paper ↗
Efficient Online Reinforcement Learning with Offline Data
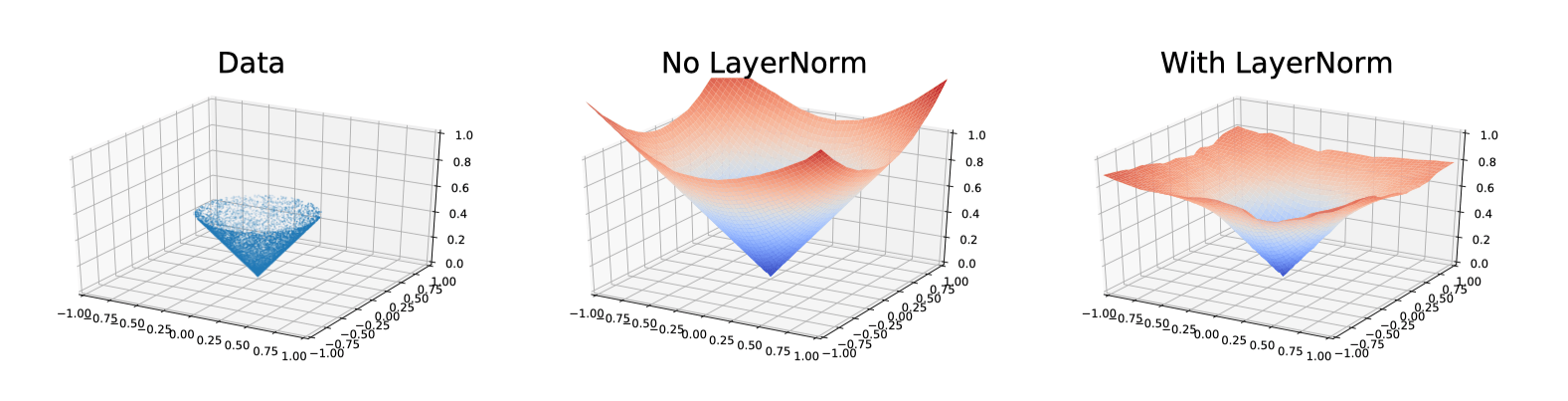
Insight#
- 对称采样:50% 在线数据 + 50% 离线数据,去除对于离线数据质量的假设
- LayerNorm 约束价值函数 Q,抑制 OOD 时的过度自信(价值外推),稳定值函数
- 高效采样:增加数据回放比 UTD,采用随机集成蒸馏(见下述算法)
Algorithm#
算法 在线强化学习结合离线数据 RLPD初始化:层归一化,集成规模 E, 梯度步数 G, 网络架构评论家参数 θ1,...,θE (θi′←θi), 策略参数 ϕ折扣因子 γ, 温度系数 α, EMA 权重 ρ, 目标子集 Z∈{1,2}经验池 R=∅, 离线数据集 D主循环:获取初始状态 s0循环 t=0 至 T:执行动作 at∼πϕ(⋅∣st), 存储转移 (st,at,rt,st+1) 至 R训练步骤 (重复 G 次):采样 bR←2N 自 R, bD←2N 自 D合并批次 b=bR∪bD计算目标值:Z←随机选取 Z 个索引(从 {1,...,E})y=r+γ[mini∈ZQθi′(s′,a~′)]+γαlogπϕ(a~′∣s′)其中 a~′∼πϕ(⋅∣s′)评论家更新:循环 i=1 至 E:θi←argminN1∑(y−Qθi(s,a))2θi′←ρθi′+(1−ρ)θi策略更新:ϕ←argmaxE1∑i=1EQθi(s,a~)−αlogπϕ(a~∣s)其中 a~∼πϕ(⋅∣s)
Result#
收敛变快(300k vs 1M),效果提升。
HIL-SERL#
Paper ↗ / Homepage ↗ / Code ↗
Human in Loop SERL,双臂任务
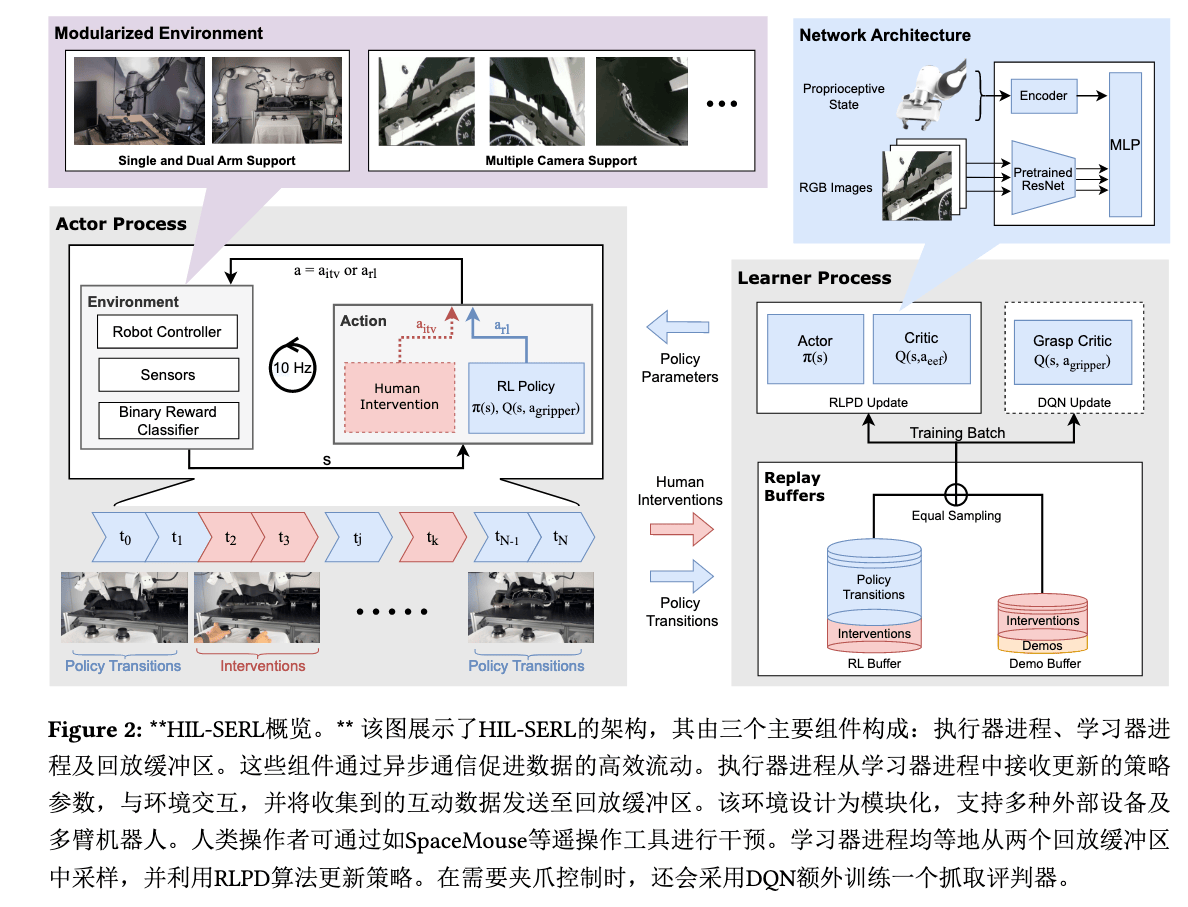
Insight#
主动学习、人在回路:系统向模型请求可能的修正,offline 更新
Arch#
Backbone:ResNet-10
Reward:01 Sparse (MLP)
AC 架构:
- Actor:采样,送到 replay buffer,可以人为干预
- Learner:学习,RLPD 均等采样
两个缓冲区:
对于人类产生的干预数据:
- actions 同时放到两个缓冲区(RL buffer + Demo buffer)
- P 概率转移只放到 RL buffer
单独用 DQN 学习抓握(夹爪建模为离散动作),输出动作基于 EEF 当前坐标系,抗干扰。
RLDG#
Paper ↗
Reinforcement Learning Distilled Generalist

Insight#
- 使用 RL 生成高质量微调数据,微调 HIL-SERL
- 数据质量 > 数据数量
ConRFT#
Paper ↗
Consistency-based Reinforced Fine-Tuning
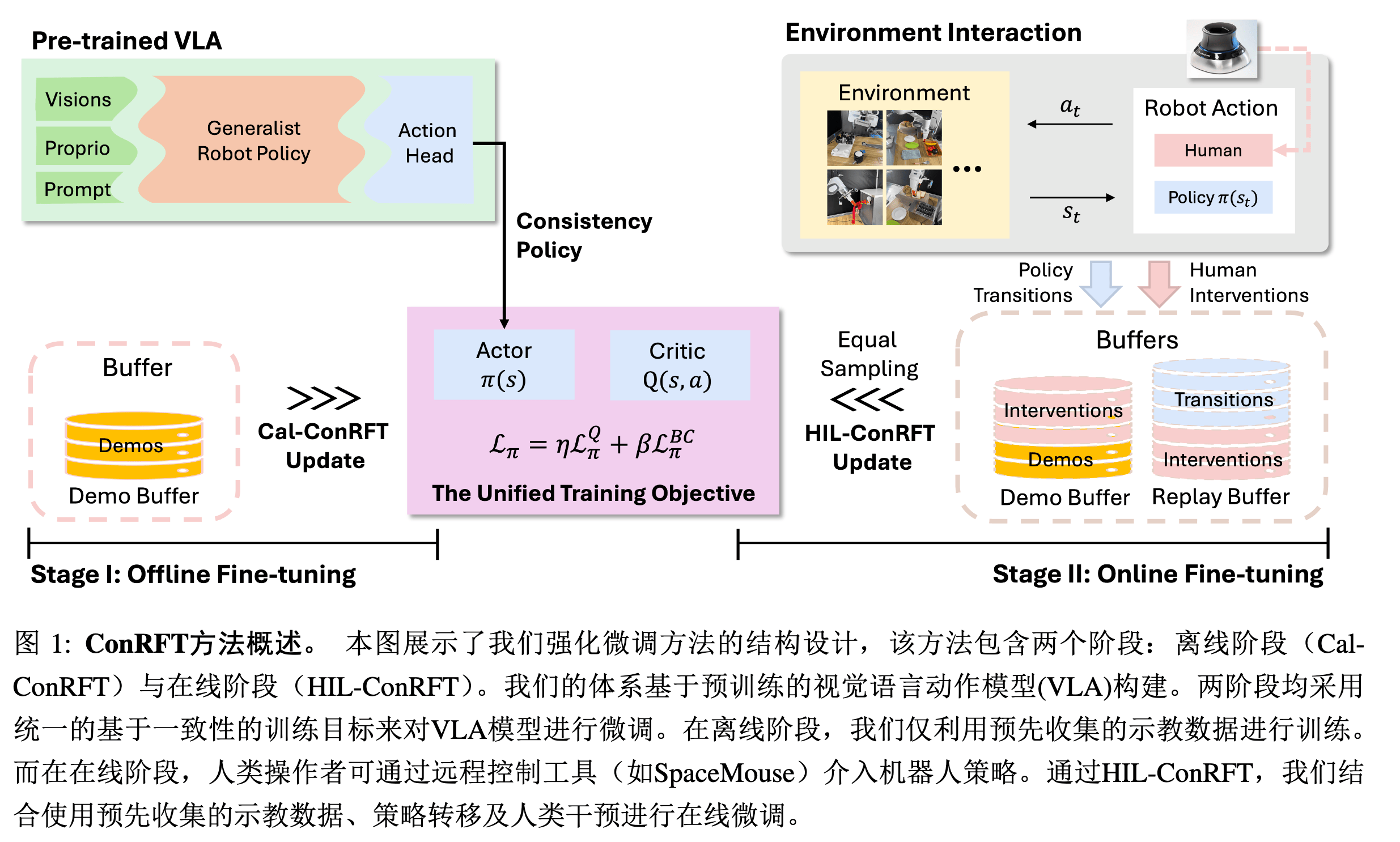
Math#
离线 Critic 损失#
LQoffline(θ)=α(Es∼D,a∼π[max(Qθ,Vμ)]−Es,a∼D[Qθ])+21E[(Qθ−BπQ)2]
- max(Qθ,Vμ):防止 OOD(分布外)动作的高估
- E[(Qθ−BπQ)2]:稳定 Q 值估计,防止离线数据不足导致的过拟合
一致性策略#
πψ(a∣s)=fψ(ak,k∣Eϕ(s))
- fψ 一致性策略是一个基于扩散模型的策略,负责去噪并生成最终动作。其目标是学习从单位高斯分布 N(0,I) 的随机噪声动作 ak 到专家动作分布 a∼π∗(a∣s) 的映射。映射过程以当前状态编码 Eϕ(s) 为条件。
- ak∼N(0,kI) 是第 k 步的含噪声动作将扩散时间步 [ϵ,K] 划分为 M 个子区间(边界为 k1=ϵ≤⋯≤kM=K),每个子区间对应一个噪声尺度 km。例如,ϵ=0.002 表示初始噪声尺度极小,K 为最大噪声尺度。
Lπoffline(ψ)=−ηE[Q(s,a)]+βE[d(fψ(a+kmz),a)]
-
−ηE[Q(s,a)]:引导策略朝高回报方向优化
-
βE[d(fψ(a+kmz),a)]:迫使策略在不同噪声尺度下保持动作预测的一致性,也即约束动作与演示数据的一致,解决人类演示的次优问题
对任意中间扩散步 km,若向专家动作 a 添加噪声 kmz 得到扰动动作 a+kmz,一致性策略 fψ 应能将其映射回原始专家动作 a。
Insight#
- 人在回路
- 一致性策略保证鲁棒性,但在线学习阶段逐步降低 β(BC 权重),实现从模仿到自主探索的平滑过渡
- 反馈信号中存在时间惩罚,引导快速完成任务
GRAPE#
Paper ↗
Generalizing Robot Policy via Preference Alignment
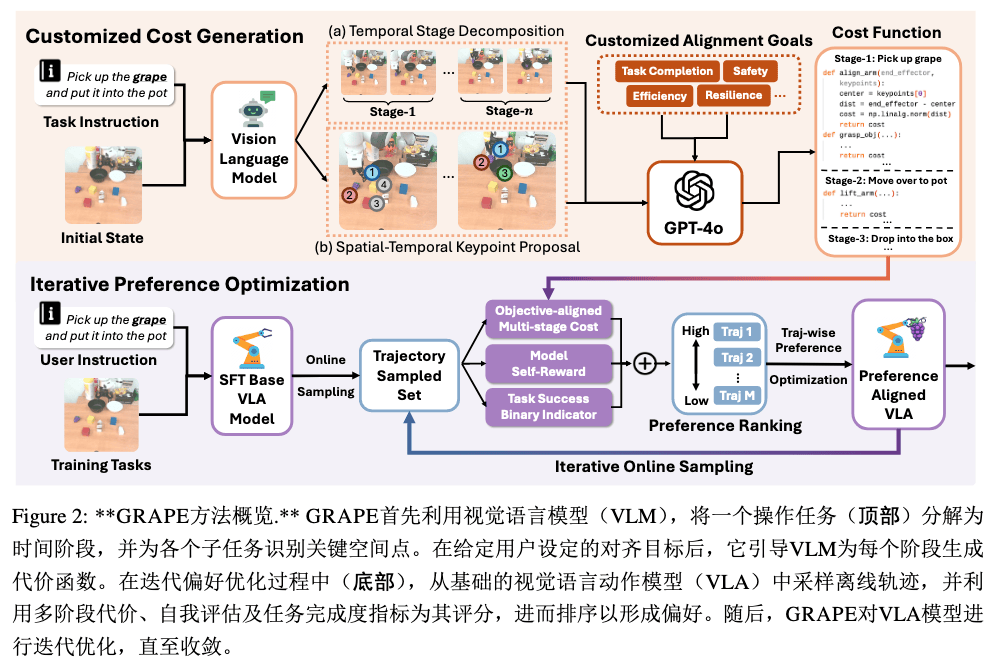
Math#
TPO 轨迹偏好优化损失(Trajectory-wise Preference Optimization Loss,类似 DPO):
LTPO=−E[logσ(β(logπref(ζw)πθ(ζw)−logπref(ζl)πθ(ζl)))]
- β:温度系数,调节策略更新的强度(类比 “学习率”),越大这个 Loss 也越大,策略对比越强,更关注优选 / 劣选轨迹的差异;越小越保守更新,这项损失不重要。
- πθ:待优化的策略(参数为 θ)
- πref:参考策略(预训练的初始策略)
- ζw,ζl:优选轨迹(winning)和劣选轨迹(losing)
Insight#
-
对比学习,增大优选轨迹概率比,降低劣选轨迹概率比
-
存在外部 Critic,由强大 LLM(GPT4o)给出,而非手动设计,某一时刻的成本为后续成本的乘积:
Rext(ζ)=i=1∏Se−CSi({κSi})
其中:
- S:子系统的总数
- {κSi}:子任务 Si 的动态参数集合,如关节角度、速度、接触力等实时状态
- CSi:子任务 Si 的成本函数,由 LLM 给出
-
完整的 Reward 同时包括外部 Critic、模型自身、以及成功与否信息加权,用以判断 ζw,ζl:
RGCPG(ζ)=λ1Rself(ζ)+λ2Rext(ζ)+λ3Isuccess(ζ)
其中:
Rself(ζ)=log(π(ζ,q))=log(i=1∏Tπ(ai∣(oi,q)))
Algorithm#
算法 迭代偏好优化算法初始化:基础 VLA 策略 πθ, 任务指令集 Q={qi}, 阶段分解器 MD最大迭代次数 K, 奖励权重 {λ1,λ2,λ3}阶段关键点 {κSi}, 成本函数 {CjSi} 及阈值 {τjSi}主循环:循环 k=1 至 K:用 πθ 和 Q 采样轨迹集 Dk={ζi}i=1M循环轨迹 ζ∈Dk:分解 ζ 为多阶段 S (阶段分解)计算各阶段成本 CSi (阶段成本)计算外部奖励 Rext(ζ) (全局成本)计算策略自奖励 Rself(ζ) (轨迹自评估)验证任务成功指标 Isuccess(ζ) (成功判别)聚合 GCPG 奖励 RGCPG(ζ) (综合奖励)按 RGCPG(ζ) 排序 Dk从 top-m 和 bottom-m轨迹生成配对 {ζw,ζl}用 TPO 损失更新 πθ (偏好对齐)返回:优化策略 π∗
ASAP#
Paper ↗
Aligning Simulation and Real-World Physics
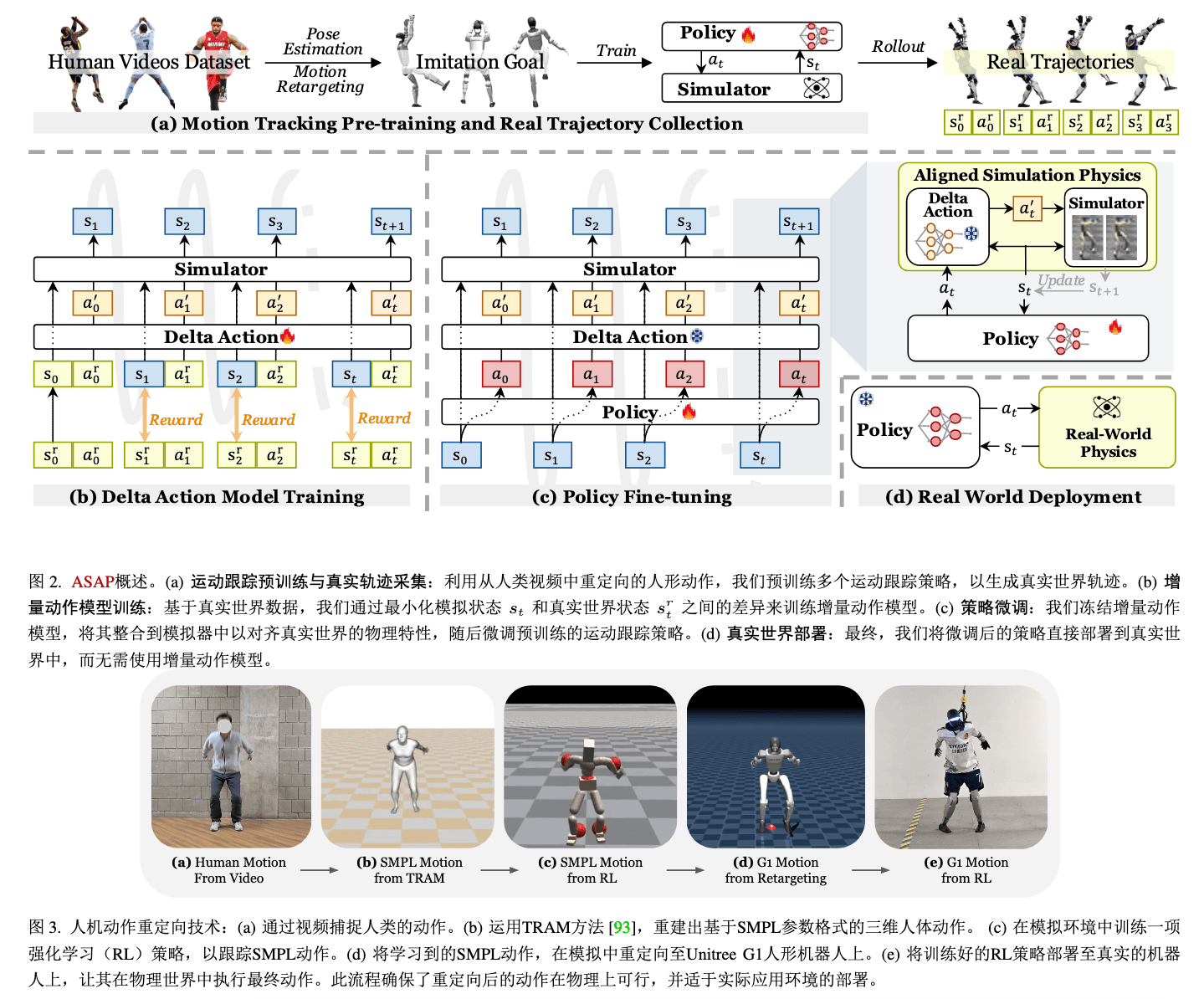
Insight#
-
预训练得到基础策略(模拟环境中)
-
后训练收集现实数据,模拟重放,获取跟踪误差,训练 delta 模型来补偿差异,形成残差校正项,通过动作空间修正隐式补偿,而不是像 SysID 一样显式建模物理参数来修正差异
骑自行车时,人脑自动补偿重心偏移,而非计算力学方程
st+1=fASAP(st,at)=fsim(st,at+πΔ(st,at))
-
非对称 AC 架构
- Actor 网络仅依赖本体感知输入(关节位置 / 速度、基座姿态、时间相位)
- Critic 网络额外访问特权信息(参考动作轨迹、全局位置)
Arch#
- PPO,AC
- Reward:rt=rtask+rpenalty+rregularization
- 任务奖励(身体位置 / 旋转 / 速度匹配)
- 惩罚项(关节极限、扭矩超限)
- 正则化(动作平滑性)