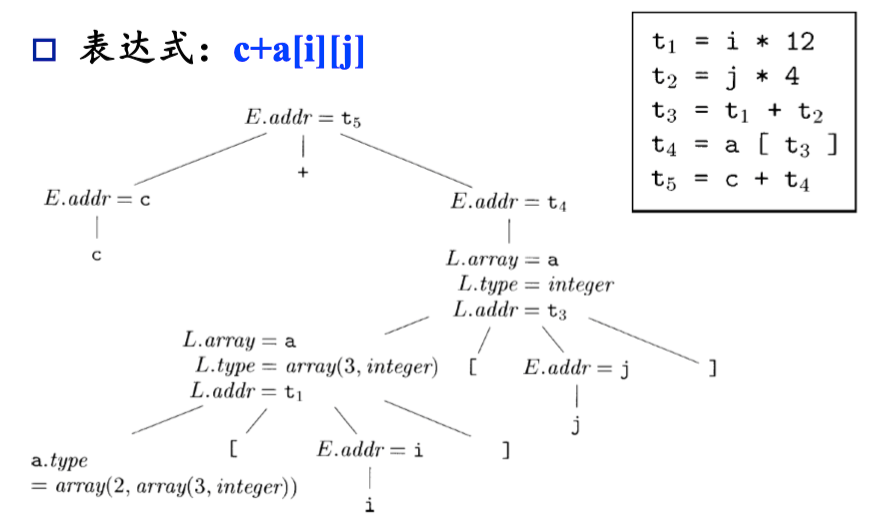
生成表达式代码的 SDD#
产生式 语义规则 S → id = E ; S . code = E . code ∥ gen ( top.get(id.lexeme) = E . addr ) E → E 1 + E 2 E . addr = new Temp() E . code = E 1 . code ∥ E 2 . code ∥ gen ( E . addr = E 1 . addr + E 2 . addr ) E → ∣ − E 1 E . addr = new Temp() E . code = E 1 . code ∥ gen ( E . addr = “minus” E 1 . addr ) E → ∣ ( E 1 ) E . addr = E 1 . addr E . code = E 1 . code E → ∣ id E . addr = top.get(id.lexeme) E . code = “” \begin{array}{|ll|}
\hline
\text{产生式} & \text{语义规则} \\
\hline
S \to \text{id} = E ; & S.\text{code} = E.\text{code} \parallel \\
& \quad \text{gen}(\text{top.get(id.lexeme)} = E.\text{addr}) \\
\hline
E \to E_1 + E_2 & E.\text{addr} = \text{new Temp()} \\
& E.\text{code} = E_1.\text{code} \parallel E_2.\text{code} \parallel \\
& \quad \text{gen}(E.\text{addr} = E_1.\text{addr} + E_2.\text{addr}) \\
\hline
\phantom{E \to \ }| - E_1 & E.\text{addr} = \text{new Temp()} \\
& E.\text{code} = E_1.\text{code} \parallel \\
& \quad \text{gen}(E.\text{addr} = \text{“minus”} E_1.\text{addr}) \\
\hline
\phantom{E \to \ }| ( E_1 ) & E.\text{addr} = E_1.\text{addr} \\
& E.\text{code} = E_1.\text{code} \\
\hline
\phantom{E \to \ }| \text{id} & E.\text{addr} = \text{top.get(id.lexeme)} \\
& E.\text{code} = \text{“”} \\
\hline
\end{array} 产生式 S → id = E ; E → E 1 + E 2 E → ∣ − E 1 E → ∣ ( E 1 ) E → ∣ id 语义规则 S . code = E . code ∥ gen ( top.get(id.lexeme) = E . addr ) E . addr = new Temp() E . code = E 1 . code ∥ E 2 . code ∥ gen ( E . addr = E 1 . addr + E 2 . addr ) E . addr = new Temp() E . code = E 1 . code ∥ gen ( E . addr = “minus” E 1 . addr ) E . addr = E 1 . addr E . code = E 1 . code E . addr = top.get(id.lexeme) E . code = “” 其中:
综合属性 code \text{code} code
addr \text{addr} addr top.get ( ⋯ ) \text{top.get}(\cdots) top.get ( ⋯ ) id \text{id} id new Temp ( ) \text{new} \, \text{Temp}() new Temp ( ) gen ( ⋯ ) \text{gen}(\cdots) gen ( ⋯ )
这里实际上是一个增量式翻译,即要运算得到 c = a + b,先翻译出生成 a 和 b 的代码,再翻译生成 c 的代码。
数组元素#
数组元素的寻址#
一维数组的寻址#
假设数组元素被存放在连续的存储空间中,元素从 0 到 n − 1 n-1 n − 1 i i i
base + i ⋅ w \text{base} + i \cdot w base + i ⋅ w 其中:
base \text{base} base A A A A [ 0 ] A[0] A [ 0 ] w w w base \text{base} base w w w n n n
k 维数组的寻址#
假设数组按行存放,即首先存放 A [ 0 ] [ i 2 ] . . . [ i k ] A[0][i_2]...[i_k] A [ 0 ] [ i 2 ] ... [ i k ] A [ 1 ] [ i 2 ] . . . [ i k ] A[1][i_2]...[i_k] A [ 1 ] [ i 2 ] ... [ i k ]
设 n j n_j n j j j j w j w_j w j j j j w k = w w_k = w w k = w
w k − 1 = n k ⋅ w k = n k ⋅ w w k − 2 = n k − 1 ⋅ w k − 1 = n k − 1 ⋅ n k ⋅ w \begin{aligned}
w_{k-1} &= n_k \cdot w_k = n_k \cdot w \\
w_{k-2} &= n_{k-1} \cdot w_{k-1} = n_{k-1} \cdot n_k \cdot w
\end{aligned} w k − 1 w k − 2 = n k ⋅ w k = n k ⋅ w = n k − 1 ⋅ w k − 1 = n k − 1 ⋅ n k ⋅ w 多维数组 A [ i 1 ] [ i 2 ] . . . [ i k ] A[i_1][i_2]...[i_k] A [ i 1 ] [ i 2 ] ... [ i k ]
base + i 1 ⋅ w 1 + i 2 ⋅ w 2 + . . . + i k ⋅ w k \text{base} + i_1 \cdot w_1 + i_2 \cdot w_2 + ... + i_k \cdot w_k base + i 1 ⋅ w 1 + i 2 ⋅ w 2 + ... + i k ⋅ w k 或者:
base + ( ( ( . . . ( ( i 1 ⋅ n 2 + i 2 ) ⋅ n 3 + i 3 ) . . . ) ⋅ n k ) + i k ) ⋅ w \text{base} + (((...((i_1 \cdot n_2 + i_2) \cdot n_3 + i_3)...) \cdot n_k) + i_k) \cdot w base + ((( ... (( i 1 ⋅ n 2 + i 2 ) ⋅ n 3 + i 3 ) ... ) ⋅ n k ) + i k ) ⋅ w 多维数组的存放方法#
求 a [ i ] a[i] a [ i ]
base + ( i − low ) ⋅ w = base − low ⋅ w + i ⋅ w \text{base} + (i - \text{low}) \cdot w = \text{base} - \text{low} \cdot w + i \cdot w base + ( i − low ) ⋅ w = base − low ⋅ w + i ⋅ w 注意,这里 low \text{low} low 其不一定为 0。
包含数组元素的表达式文法#
添加新的文法产生式#
数组元素 L : L → L [ E ] ∣ i d [ E ] L: L \rightarrow L[E] \ | \ id[E] L : L → L [ E ] ∣ i d [ E ]
以数组元素为左部的赋值 S → L = E S \rightarrow L = E S → L = E
数组元素作为表达式中的因子 E → L E \rightarrow L E → L
翻译方案#
计算偏移量:对 L L L L . addr L.\text{addr} L . addr
综合属性 array \text{array} array
数组元素作为因子
数组元素作为赋值左部
使用三地址指令 a [ i ] = x a[i] = x a [ i ] = x
产生式 语义规则 L → id [ E ] L . array = top.get(id.lexeme) L . type = L . array.type.elem L . addr = new Temp() gen ( L . addr = E . addr ∗ L . type.width ) L → ∣ L 1 [ E ] L . array = L 1 . array L . type = L 1 . type.elem t = new Temp() L . addr = new Temp() gen ( t = E . addr ∗ L . type.width ) gen ( L . addr = L 1 . addr + t ) E → E 1 + E 2 E . addr = new Temp() gen ( E . addr = E 1 . addr + E 2 . addr ) E → ∣ id E . addr = top.get(id.lexeme) E → ∣ L E . addr = new Temp() gen ( E . addr = L . array.base [ L . addr ] ) S → id = E ; gen ( top.get(id.lexeme) = E . addr ) S → ∣ L = E ; gen ( L . array.base [ L . addr ] = E . addr ) \begin{array}{|ll|}
\hline
\text{产生式} & \text{语义规则} \\
\hline
L \to \text{id} [ E ] & L.\text{array} = \text{top.get(id.lexeme)} \\
& L.\text{type} = L.\text{array.type.elem} \\
& L.\text{addr} = \text{new Temp()} \\
& \text{gen}(L.\text{addr} = E.\text{addr} * L.\text{type.width}) \\
\hline
\phantom{L \to \ }| L_1 [ E ] & L.\text{array} = L_1.\text{array} \\
& L.\text{type} = L_1.\text{type.elem} \\
& t = \text{new Temp()} \\
& L.\text{addr} = \text{new Temp()} \\
& \text{gen}(t = E.\text{addr} * L.\text{type.width}) \\
& \text{gen}(L.\text{addr} = L_1.\text{addr} + t) \\
\hline
E \to E_1 + E_2 & E.\text{addr} = \text{new Temp()} \\
& \text{gen}(E.\text{addr} = E_1.\text{addr} + E_2.\text{addr}) \\
\hline
\phantom{E \to \ }| \text{id} & E.\text{addr} = \text{top.get(id.lexeme)} \\
\hline
\phantom{E \to \ }| L & E.\text{addr} = \text{new Temp()} \\
& \text{gen}(E.\text{addr} = L.\text{array.base} [ L.\text{addr} ]) \\
\hline
S \to \text{id} = E ; & \text{gen}(\text{top.get(id.lexeme)} = E.\text{addr}) \\
\hline
\phantom{S \to \ }| L = E ; & \text{gen}(L.\text{array.base} [ L.\text{addr} ] = E.\text{addr}) \\
\hline
\end{array} 产生式 L → id [ E ] L → ∣ L 1 [ E ] E → E 1 + E 2 E → ∣ id E → ∣ L S → id = E ; S → ∣ L = E ; 语义规则 L . array = top.get(id.lexeme) L . type = L . array.type.elem L . addr = new Temp() gen ( L . addr = E . addr ∗ L . type.width ) L . array = L 1 . array L . type = L 1 . type.elem t = new Temp() L . addr = new Temp() gen ( t = E . addr ∗ L . type.width ) gen ( L . addr = L 1 . addr + t ) E . addr = new Temp() gen ( E . addr = E 1 . addr + E 2 . addr ) E . addr = top.get(id.lexeme) E . addr = new Temp() gen ( E . addr = L . array.base [ L . addr ]) gen ( top.get(id.lexeme) = E . addr ) gen ( L . array.base [ L . addr ] = E . addr ) 注意:
这里不是在算数组的类型大小,而是在算一个数组表达式的相对于基地址的偏移量。
addr \text{addr} addr array \text{array} array 建议结合例子观察一下 type \text{type} type
这里省略了一些 gen \text{gen} gen
类型检查和转换#
类型系统 (type system)#
给每一个组成部分赋予一个类型表达式
通过一组逻辑规则来表示这些类型表达式必须满足的条件
设计类型系统的根本目的是用静态检查的方式来保证合法程序运行时的良行为。
类型检查规则#
类型综合 :根据子表达式的类型构造出表达式的类型
例如:
如果 f f f s → t s \rightarrow t s → t x x x s s s
那么 f ( x ) f(x) f ( x ) t t t
类型推导 :根据语言结构的使用方式来确定该结构的类型
例如:
如果 f ( x ) f(x) f ( x ) f f f α → β \alpha \rightarrow \beta α → β x x x α \alpha α
那么 f ( x ) f(x) f ( x ) β \beta β
α , β \alpha, \beta α , β
类型转换#
假设在表达式 x ∗ i x * i x ∗ i x x x i i i
x x x i i i 浮点数 * 和整数 * 使用不同的指令
例如:
t 1 = ( float ) i t_1 = (\text{float}) i t 1 = ( float ) i t 2 = x fmul t 1 t_2 = x \; \text{fmul} \; t_1 t 2 = x fmul t 1
处理简单的类型转换的 SDD:
产生式 语义规则 E → E 1 + E 2 if ( E 1 . type = integer and E 2 . type = integer ) E . type = integer else if ( E 1 . type = float and E 2 . type = integer ) E . type = float \begin{array}{|ll|}
\hline
\text{产生式} & \text{语义规则} \\
\hline
E \to E_1 + E_2 & \text{if } (E_1.\text{type} = \text{integer} \text{ and } E_2.\text{type} = \text{integer}) E.\text{type} = \text{integer} \\
& \text{else if } (E_1.\text{type} = \text{float} \text{ and } E_2.\text{type} = \text{integer}) E.\text{type} = \text{float} \\
\hline
\end{array} 产生式 E → E 1 + E 2 语义规则 if ( E 1 . type = integer and E 2 . type = integer ) E . type = integer else if ( E 1 . type = float and E 2 . type = integer ) E . type = float 类型拓宽和类型收缩#
编译器自动完成的转换为 隐式转换(coercion)
程序员用代码指定的强制转换为 显式转换(cast)
处理类型转换的 SDT#
产生式 语义规则 E → E 1 + E 2 E . type = max ( E 1 . type , E 2 . type ) ; a 1 = widen ( E 1 . addr , E 1 . type , E . type ) ; a 2 = widen ( E 2 . addr , E 2 . type , E . type ) ; E . addr = new Temp ( ) ; gen ( E . addr “=” a 1 “+” a 2 ) ; \begin{array}{|ll|}
\hline
\text{产生式} & \text{语义规则} \\
\hline
E \to E_1 + E_2 & E.\text{type} = \max(E_1.\text{type}, E_2.\text{type}); \\
& a_1 = \text{widen}(E_1.\text{addr}, E_1.\text{type}, E.\text{type}); \\
& a_2 = \text{widen}(E_2.\text{addr}, E_2.\text{type}, E.\text{type}); \\
& E.\text{addr} = \text{new Temp}(); \\
& \text{gen}(E.\text{addr} \text{ “=” } a_1 \text{ “+” } a_2); \\
\hline
\end{array} 产生式 E → E 1 + E 2 语义规则 E . type = max ( E 1 . type , E 2 . type ) ; a 1 = widen ( E 1 . addr , E 1 . type , E . type ) ; a 2 = widen ( E 2 . addr , E 2 . type , E . type ) ; E . addr = new Temp ( ) ; gen ( E . addr “=” a 1 “+” a 2 ) ; widen 函数用于将一个地址的值转换为指定的类型。其定义如下:
Addr widen ( Addr a , Type t , Type w ) { if (t == w) return a; else if (t == integer && w == float ) { Addr temp = new Temp (); gen (temp '=' '(float)' a); // 就是这里发生了隐式类型转换 return temp; } else error; } cpp
max 函数用于查找两个类型的最小公共祖先。具体实现依赖于类型系统的定义。widen 函数生成必要的类型转换代码,并返回转换后的地址。
函数/运算符的重载#
通过查看参数来解决函数重载问题:
产生式 语义规则 E → f ( E 1 ) if f . typeset = { s i → t i ∣ 1 ≤ i ≤ k } and E 1 . type = s k then E . type = t k \begin{array}{|ll|}
\hline
\text{产生式} & \text{语义规则} \\
\hline
E \to f(E_1) & \text{if } f.\text{typeset} = \{s_i \to t_i \mid 1 \leq i \leq k\} \text{ and } E_1.\text{type} = s_k \text{ then } E.\text{type} = t_k \\
\hline
\end{array} 产生式 E → f ( E 1 ) 语义规则 if f . typeset = { s i → t i ∣ 1 ≤ i ≤ k } and E 1 . type = s k then E . type = t k 控制流的翻译#
布尔表达式可以用于改变控制流/计算逻辑值:
文法:
B → B ∣ ∣ B ∣ B & & B ∣ ! B ∣ ( B ) ∣ E rel E ∣ true ∣ false B \to B \, || \, B \mid B \, \&\& \, B \mid !B \mid (B) \mid E \, \text{rel} \, E \mid \text{true} \mid \text{false} B → B ∣∣ B ∣ B && B ∣ ! B ∣ ( B ) ∣ E rel E ∣ true ∣ false 短路求值:
B 1 ∣ ∣ B 2 B_1 \, || \, B_2 B 1 ∣∣ B 2 B 1 B_1 B 1 B 2 B_2 B 2 B 1 & & B 2 B_1 \, \&\& \, B_2 B 1 && B 2 B 1 B_1 B 1 B 2 B_2 B 2
短路代码通过跳转指令实现控制流的处理,逻辑运算符本身不在代码中出现。
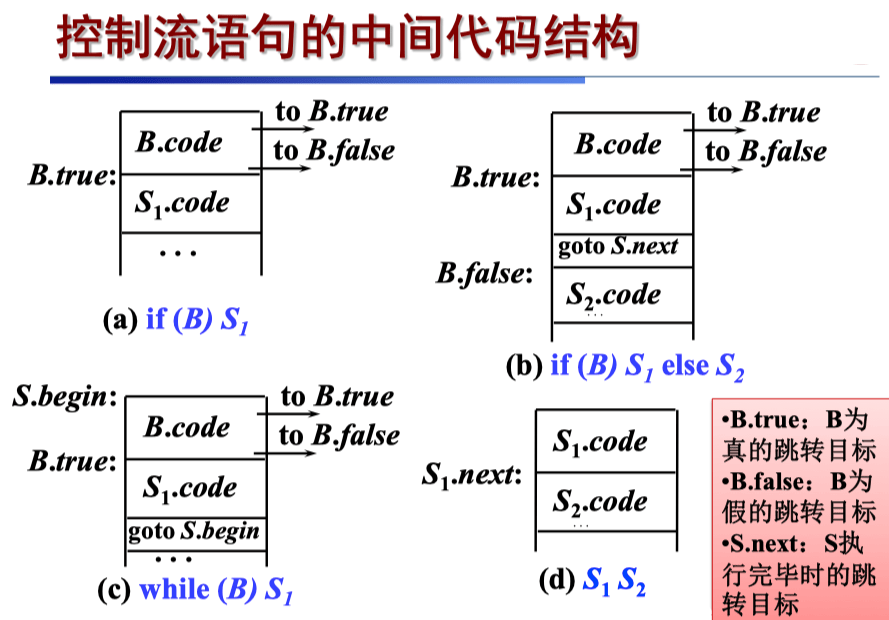
控制流语句的 SDD#
产生式 语义规则 P → S S . next = newlabel() P . code = S . code ∥ label ( S . next ) S → assign S . code = assign.code S → if ( B ) S 1 B . true = newlabel() B . false = S 1 . next = S . next S . code = B . code ∥ label ( B . true ) ∥ S 1 . code S → if ( B ) S 1 else S 2 B . true = newlabel() B . false = newlabel() S 1 . next = S 2 . next = S . next S . code = B . code ∥ label ( B . true ) ∥ S 1 . code ∥ gen ( “goto” S . next ) ∥ label ( B . false ) ∥ S 2 . code S → while ( B ) S 1 begin = newlabel() B . true = newlabel() B . false = S . next S 1 . next = begin S . code = label ( begin ) ∥ B . code ∥ label ( B . true ) ∥ S 1 . code ∥ gen ( “goto”begin ) S → S 1 S 2 S 1 . next = newlabel() S 2 . next = S . next S . code = S 1 . code ∥ label ( S 1 . next ) ∥ S 2 . code \begin{array}{|ll|}
\hline
\text{产生式} & \text{语义规则} \\
\hline
P \to S & S.\text{next} = \text{newlabel()} \\
& P.\text{code} = S.\text{code} \parallel \text{label}(S.\text{next}) \\
\hline
S \to \text{assign} & S.\text{code} = \text{assign.code} \\
\hline
S \to \text{if} (B) S_1 & B.\text{true} = \text{newlabel()} \\
& B.\text{false} = S_1.\text{next} = S.\text{next} \\
& S.\text{code} = B.\text{code} \parallel \text{label}(B.\text{true}) \parallel S_1.\text{code} \\
\hline
S \to \text{if} (B) S_1 \text{ else } S_2 & B.\text{true} = \text{newlabel()} \\
& B.\text{false} = \text{newlabel()} \\
& S_1.\text{next} = S_2.\text{next} = S.\text{next} \\
& S.\text{code} = B.\text{code} \parallel \text{label}(B.\text{true}) \parallel S_1.\text{code} \\
& \quad \parallel \text{gen}(\text{“goto”} S.\text{next}) \parallel \text{label}(B.\text{false}) \parallel S_2.\text{code} \\
\hline
S \to \text{while} (B) S_1 & \text{begin} = \text{newlabel()} \\
& B.\text{true} = \text{newlabel()} \\
& B.\text{false} = S.\text{next} \\
& S_1.\text{next} = \text{begin} \\
& S.\text{code} = \text{label}(\text{begin}) \parallel B.\text{code} \parallel \text{label}(B.\text{true}) \parallel S_1.\text{code} \parallel \text{gen}(\text{“goto”} \text{begin}) \\
\hline
S \to S_1 S_2 & S_1.\text{next} = \text{newlabel()} \\
& S_2.\text{next} = S.\text{next} \\
& S.\text{code} = S_1.\text{code} \parallel \text{label}(S_1.\text{next}) \parallel S_2.\text{code} \\
\hline
\end{array} 产生式 P → S S → assign S → if ( B ) S 1 S → if ( B ) S 1 else S 2 S → while ( B ) S 1 S → S 1 S 2 语义规则 S . next = newlabel() P . code = S . code ∥ label ( S . next ) S . code = assign.code B . true = newlabel() B . false = S 1 . next = S . next S . code = B . code ∥ label ( B . true ) ∥ S 1 . code B . true = newlabel() B . false = newlabel() S 1 . next = S 2 . next = S . next S . code = B . code ∥ label ( B . true ) ∥ S 1 . code ∥ gen ( “goto” S . next ) ∥ label ( B . false ) ∥ S 2 . code begin = newlabel() B . true = newlabel() B . false = S . next S 1 . next = begin S . code = label ( begin ) ∥ B . code ∥ label ( B . true ) ∥ S 1 . code ∥ gen ( “goto” begin ) S 1 . next = newlabel() S 2 . next = S . next S . code = S 1 . code ∥ label ( S 1 . next ) ∥ S 2 . code 重点在于理解标号的顺序,明白基本块之间是怎么跳转的 ,其实如果自己做完 Lab Lv6 基本上就很简单了。
布尔表达式控制流翻译#
生成的代码执行时跳转到两个标号之一:
表达式的值为真时,跳转到 B . true B.\text{true} B . true
表达式的值为假时,跳转到 B . false B.\text{false} B . false
B . true B.\text{true} B . true B . false B.\text{false} B . false B B B
如果 B B B
如果没有 else 分支,则 B . false B.\text{false} B . false
如果 B B B
下图的代码中同时考虑了短路求值 :
产生式 语义规则 B → B 1 ∣ ∣ B 2 B 1 . true = B . true ; B 1 . false = newlabel() ; B 2 . true = B . true ; B 2 . false = B . false ; B . code = B 1 . code ∥ label ( B 1 . false ) ∥ B 2 . code B → B 1 & & B 2 B 1 . true = newlabel() ; B 1 . false = B . false ; B 2 . true = B . true ; B 2 . false = B . false ; B . code = B 1 . code ∥ label ( B 1 . true ) ∥ B 2 . code B → ! B 1 B 1 . true = B . false ; B 1 . false = B . true ; B . code = B 1 . code B → ( B 1 ) B 1 . true = B . true ; B 1 . false = B . false ; B . code = B 1 . code B → E 1 rel E 2 B . code = gen ( “if” E 1 . addr rel.op E 2 . addr “goto” B . true ) ∥ gen ( “goto” B . false ) B → true B . code = gen ( “goto” B . true ) B → false B . code = gen ( “goto” B . false ) \begin{array}{|ll|}
\hline
\text{产生式} & \text{语义规则} \\
\hline
B \to B_1 || B_2 & B_1.\text{true} = B.\text{true}; B_1.\text{false} = \text{newlabel()}; \\
& B_2.\text{true} = B.\text{true}; B_2.\text{false} = B.\text{false}; \\
& B.\text{code} = B_1.\text{code} \parallel \text{label}(B_1.\text{false}) \parallel B_2.\text{code} \\
\hline
B \to B_1 \&\& B_2 & B_1.\text{true} = \text{newlabel()}; B_1.\text{false} = B.\text{false}; \\
& B_2.\text{true} = B.\text{true}; B_2.\text{false} = B.\text{false}; \\
& B.\text{code} = B_1.\text{code} \parallel \text{label}(B_1.\text{true}) \parallel B_2.\text{code} \\
\hline
B \to ! B_1 & B_1.\text{true} = B.\text{false}; B_1.\text{false} = B.\text{true}; B.\text{code} = B_1.\text{code} \\
\hline
B \to (B_1) & B_1.\text{true} = B.\text{true}; B_1.\text{false} = B.\text{false}; B.\text{code} = B_1.\text{code} \\
\hline
B \to E_1 \text{ rel } E_2 & B.\text{code} = \text{gen}(\text{“if”} E_1.\text{addr } \text{rel.op } E_2.\text{addr } \text{“goto”} B.\text{true}) \parallel \text{gen}(\text{“goto”} B.\text{false}) \\
\hline
B \to \text{true} & B.\text{code} = \text{gen}(\text{“goto”} B.\text{true}) \\
\hline
B \to \text{false} & B.\text{code} = \text{gen}(\text{“goto”} B.\text{false}) \\
\hline
\end{array} 产生式 B → B 1 ∣∣ B 2 B → B 1 && B 2 B → ! B 1 B → ( B 1 ) B → E 1 rel E 2 B → true B → false 语义规则 B 1 . true = B . true ; B 1 . false = newlabel() ; B 2 . true = B . true ; B 2 . false = B . false ; B . code = B 1 . code ∥ label ( B 1 . false ) ∥ B 2 . code B 1 . true = newlabel() ; B 1 . false = B . false ; B 2 . true = B . true ; B 2 . false = B . false ; B . code = B 1 . code ∥ label ( B 1 . true ) ∥ B 2 . code B 1 . true = B . false ; B 1 . false = B . true ; B . code = B 1 . code B 1 . true = B . true ; B 1 . false = B . false ; B . code = B 1 . code B . code = gen ( “if” E 1 . addr rel.op E 2 . addr “goto” B . true ) ∥ gen ( “goto” B . false ) B . code = gen ( “goto” B . true ) B . code = gen ( “goto” B . false ) 布尔值和跳转代码#
程序中出现布尔表达式的目的也有可能就是求出它的值,例如 x = a < b x = a < b x = a < b
处理方法:首先建立表达式的语法树,然后根据表达式的不同角色来处理。
文法:
S → id = E ; ∣ if (E) S ∣ while (E) S ∣ S S S \rightarrow \text{id} = E; \ | \ \text{if (E) S} \ | \ \text{while (E) S} \ | \ S \ S S → id = E ; ∣ if (E) S ∣ while (E) S ∣ S S E → E ∥ E ∣ E & & E ∣ E rel E ∣ … E \rightarrow E \| E \ | \ E \ \&\& \ E \ | \ E \ \text{rel} \ E \ | \ \ldots E → E ∥ E ∣ E && E ∣ E rel E ∣ …
根据 E E E
S → while (E) S1 S \rightarrow \text{while (E) S1} S → while (E) S1 E E E S → id = E S \rightarrow \text{id} = E S → id = E
在写 Lab 的时候实际上是反正值肯定返回,但是怎么用(赋值还是条件跳转)就是上一级考虑的问题了。
为布尔表达式和控制流语句生成目标代码的关键问题:某些跳转指令应该跳转到哪里?
例如: if (B) S \text{if (B) S} if (B) S
按照短路代码的翻译方法,B B B B B B
这些跳转指令的目标应该跳过 S S S S S S
如果通过语句的继承属性 next \text{next} next 当中间代码不允许符号标号时,则需要第二趟处理。
回填的基本思想#
记录 B B B goto S.next \text{goto S.next} goto S.next if ... goto S.next \text{if ... goto S.next} if ... goto S.next
这些位置被记录到 B B B B . falseList B.\text{falseList} B . falseList
当 S . next S.\text{next} S . next S S S B . falseList B.\text{falseList} B . falseList
回填技术#
生成跳转指令时暂时不指定跳转目标标号,而是使用列表记录这些不完整的指令
等知道正确的目标时再填写目标标号
每个列表中的指令都指向同一个目标 ,列表包括:truelist \text{truelist} truelist falselist \text{falselist} falselist nextlist \text{nextlist} nextlist
布尔表达式的回填翻译#
产生式 语义规则 B → B 1 ∣ ∣ M B 2 backpatch ( B 1 . falselist , M . instr ) ; B . truelist = merge ( B 1 . truelist , B 2 . truelist ) ; B . falselist = B 2 . falselist ; B → B 1 & & M B 2 backpatch ( B 1 . truelist , M . instr ) ; B . truelist = B 2 . truelist ; B . falselist = merge ( B 1 . falselist , B 2 . falselist ) ; B → ! B 1 B . truelist = B 1 . falselist ; B . falselist = B 1 . truelist ; B → ( B 1 ) B . truelist = B 1 . truelist ; B . falselist = B 1 . falselist ; B → E 1 rel E 2 B . truelist = makelist(nextinstr) ; B . falselist = makelist(nextinstr + 1) ; emit ( “if” E 1 . addr rel.op E 2 . addr “goto” B . true ) ; emit ( “goto” B . false ) ; M → ε M . instr = nextinstr ; B → true B . truelist = makelist(nextinstr) ; emit ( “goto” B . true ) ; B . falselist = null ; B → false B . falselist = makelist(nextinstr) ; emit ( “goto” B . false ) ; B . truelist = null ; \begin{array}{|ll|}
\hline
\text{产生式} & \text{语义规则} \\
\hline
B \to B_1 || M B_2 & \text{backpatch}(B_1.\text{falselist}, M.\text{instr}); \\
& B.\text{truelist} = \text{merge}(B_1.\text{truelist}, B_2.\text{truelist}); \\
& B.\text{falselist} = B_2.\text{falselist}; \\
\hline
B \to B_1 \&\& M B_2 & \text{backpatch}(B_1.\text{truelist}, M.\text{instr}); \\
& B.\text{truelist} = B_2.\text{truelist}; \\
& B.\text{falselist} = \text{merge}(B_1.\text{falselist}, B_2.\text{falselist}); \\
\hline
B \to ! B_1 & B.\text{truelist} = B_1.\text{falselist}; \\
& B.\text{falselist} = B_1.\text{truelist}; \\
\hline
B \to (B_1) & B.\text{truelist} = B_1.\text{truelist}; \\
& B.\text{falselist} = B_1.\text{falselist}; \\
\hline
B \to E_1 \text{ rel } E_2 & B.\text{truelist} = \text{makelist(nextinstr)}; \\
& B.\text{falselist} = \text{makelist(nextinstr + 1)}; \\
& \text{emit}(\text{“if”} E_1.\text{addr } \text{rel.op } E_2.\text{addr } \text{“goto” } B.\text{true}); \\
& \text{emit}(\text{“goto”} B.\text{false}); \\
\hline
M \to \varepsilon & M.\text{instr} = \text{nextinstr}; \\
\hline
B \to \text{true} & B.\text{truelist} = \text{makelist(nextinstr)}; \\
& \text{emit}(\text{“goto”} B.\text{true}); \\
& B.\text{falselist} = \text{null}; \\
\hline
B \to \text{false} & B.\text{falselist} = \text{makelist(nextinstr)}; \\
& \text{emit}(\text{“goto”} B.\text{false}); \\
& B.\text{truelist} = \text{null}; \\
\hline
\end{array} 产生式 B → B 1 ∣∣ M B 2 B → B 1 && M B 2 B → ! B 1 B → ( B 1 ) B → E 1 rel E 2 M → ε B → true B → false 语义规则 backpatch ( B 1 . falselist , M . instr ) ; B . truelist = merge ( B 1 . truelist , B 2 . truelist ) ; B . falselist = B 2 . falselist ; backpatch ( B 1 . truelist , M . instr ) ; B . truelist = B 2 . truelist ; B . falselist = merge ( B 1 . falselist , B 2 . falselist ) ; B . truelist = B 1 . falselist ; B . falselist = B 1 . truelist ; B . truelist = B 1 . truelist ; B . falselist = B 1 . falselist ; B . truelist = makelist(nextinstr) ; B . falselist = makelist(nextinstr + 1) ; emit ( “if” E 1 . addr rel.op E 2 . addr “goto” B . true ) ; emit ( “goto” B . false ) ; M . instr = nextinstr ; B . truelist = makelist(nextinstr) ; emit ( “goto” B . true ) ; B . falselist = null ; B . falselist = makelist(nextinstr) ; emit ( “goto” B . false ) ; B . truelist = null ; 首先注意:所有的语义规则都是在产生式末尾,这个表省略了大括号(后同),此时,你即将规约回产生式头,而且拥有了所有产生式体的属性(此时他们是综合属性),所以可以随便用了。
这里,引入两个综合属性:
truelist:包含跳转指令(位置)的列表,这些指令在取值 true 时执行falselist:包含跳转指令(位置)的列表,这些指令在取值 false 时执行
辅助函数包括:
makelist(i):构造一个列表merge(p1, p2):合并两个列表backpatch(p, i):用 i 回填 p 指向的语句列表中的跳转语句的跳转地址
大概讲一下,以第一个产生式 B → B 1 ∣ ∣ M B 2 B \to B_1 || M B_2 B → B 1 ∣∣ M B 2
当展开此步的时候,我们已经知道了当 B 1 B_1 B 1 B 2 B_2 B 2 M . instr M.\text{instr} M . instr B 1 . falselist B_1.\text{falselist} B 1 . falselist
但是此时还没有生成 B 2 B_2 B 2 B 1 B_1 B 1 B 2 B_2 B 2 B 1 . truelist B_1.\text{truelist} B 1 . truelist B 2 . truelist B_2.\text{truelist} B 2 . truelist B . truelist B.\text{truelist} B . truelist B B B B . truelist B.\text{truelist} B . truelist B 1 . truelist B_1.\text{truelist} B 1 . truelist B 2 . truelist B_2.\text{truelist} B 2 . truelist
当然,如果 B 2 B_2 B 2 B 2 B_2 B 2 B 1 B_1 B 1 B B B B . falselist B.\text{falselist} B . falselist B 2 . falselist B_2.\text{falselist} B 2 . falselist
控制流语句的回填翻译#
产生式 语义规则 S → if ( B ) M 1 S 1 N else M 2 S 2 backpatch ( B . truelist , M 1 . instr ) ; backpatch ( B . falselist , M 2 . instr ) ; temp = merge ( S 1 . nextlist , N . nextlist ) ; S . nextlist = merge ( temp , S 2 . nextlist ) ; S → if ( B ) then M S 1 backpatch ( B . truelist , M . instr ) ; S . nextlist = merge ( B . falselist , S 1 . nextlist ) ; N → ε N . nextlist = nextinstr ; emit ( “goto”____ ) ; / ∗ 稍后回填 ∗ / M → ε M . instr = nextinstr ; S → while M 1 ( B ) do M 2 S 1 backpatch ( S 1 . nextlist , M 1 . instr ) ; backpatch ( B . truelist , M 2 . instr ) ; S . nextlist = B . falselist ; emit ( “goto” M 1 . instr ) ; S → { L } S . nextlist = L . nextlist ; S → A S . nextlist = null ; L → L 1 M S backpatch ( L 1 . nextlist , M . instr ) ; L . nextlist = S . nextlist ; L → S L . nextlist = S . nextlist ; \begin{array}{|ll|}
\hline
\text{产生式} & \text{语义规则} \\
\hline
S \to \text{if} (B) \ M_1 \ S_1 \ N \ \text{else} \ M_2 \ S_2 & \text{backpatch}(B.\text{truelist}, M_1.\text{instr}); \\
& \text{backpatch}(B.\text{falselist}, M_2.\text{instr}); \\
& \text{temp} = \text{merge}(S_1.\text{nextlist}, N.\text{nextlist}); \\
& S.\text{nextlist} = \text{merge}(\text{temp}, S_2.\text{nextlist}); \\
\hline
S \to \text{if} (B) \ \text{then} \ M \ S_1 & \text{backpatch}(B.\text{truelist}, M.\text{instr}); \\
& S.\text{nextlist} = \text{merge}(B.\text{falselist}, S_1.\text{nextlist}); \\
\hline
N \to \varepsilon & N.\text{nextlist} = \text{nextinstr}; \\
& \text{emit}(\text{“goto”\_\_\_\_}); /* 稍后回填 */ \\
\hline
M \to \varepsilon & M.\text{instr} = \text{nextinstr}; \\
\hline
S \to \text{while} \ M_1 \ (B) \ \text{do} \ M_2 \ S_1 & \text{backpatch}(S_1.\text{nextlist}, M_1.\text{instr}); \\
& \text{backpatch}(B.\text{truelist}, M_2.\text{instr}); \\
& S.\text{nextlist} = B.\text{falselist}; \\
& \text{emit}(\text{“goto”} M_1.\text{instr}); \\
\hline
S \to \{ L \} & S.\text{nextlist} = L.\text{nextlist}; \\
\hline
S \to A & S.\text{nextlist} = \text{null}; \\
\hline
L \to L_1 \ M \ S & \text{backpatch}(L_1.\text{nextlist}, M.\text{instr}); \\
& L.\text{nextlist} = S.\text{nextlist}; \\
\hline
L \to S & L.\text{nextlist} = S.\text{nextlist}; \\
\hline
\end{array} 产生式 S → if ( B ) M 1 S 1 N else M 2 S 2 S → if ( B ) then M S 1 N → ε M → ε S → while M 1 ( B ) do M 2 S 1 S → { L } S → A L → L 1 M S L → S 语义规则 backpatch ( B . truelist , M 1 . instr ) ; backpatch ( B . falselist , M 2 . instr ) ; temp = merge ( S 1 . nextlist , N . nextlist ) ; S . nextlist = merge ( temp , S 2 . nextlist ) ; backpatch ( B . truelist , M . instr ) ; S . nextlist = merge ( B . falselist , S 1 . nextlist ) ; N . nextlist = nextinstr ; emit ( “goto”____ ) ; / ∗ 稍后回填 ∗ / M . instr = nextinstr ; backpatch ( S 1 . nextlist , M 1 . instr ) ; backpatch ( B . truelist , M 2 . instr ) ; S . nextlist = B . falselist ; emit ( “goto” M 1 . instr ) ; S . nextlist = L . nextlist ; S . nextlist = null ; backpatch ( L 1 . nextlist , M . instr ) ; L . nextlist = S . nextlist ; L . nextlist = S . nextlist ; 和之前大差不差。
Break 和 Continue 语句的处理方法#
Break 语句:
追踪外围语句 S S S
生成一个跳转指令坯
将这个指令坯的位置加入到 S . nextlist S.\text{nextlist} S . nextlist
跟踪的方法:
在符号表中设置 break \text{break} break
在符号表中设置指向 S . nextlist S.\text{nextlist} S . nextlist nextlist \text{nextlist} nextlist
Switch 语句的生成式#
为了构造 switch 语句的翻译方案,设置一个队列变量 q q q
q q q c c c d d d case 后面的常量值 v v v test 后面的条件转移语句时使用
Switch 语句的翻译方案#
产生式 语义规则 S → switch ( E ) H { M default : F L } S . nextlist = merge ( M . nextlist , L . nextlist , makelist ( nextinstr ) ) emit ( ‘goto-’ ) backpatch ( H . list , nextinstr ) for t in q : gen ( ‘if’ E . addr ‘==’ t . c ‘goto’ t . d ) emit ( ‘goto’ F . instr ) H → ε set q as ∅ H . list = makelist ( nextinstr ) emit ( ‘goto-’ ) F → ε F . instr = nextinstr M → case C : F L t . c = C . val t . d = F . instr insert t into q M . nextlist = merge ( L . nextlist , makelist ( nextinstr ) ) emit ( ‘goto-’ ) M → M 1 case C : F L t . c = C . val t . d = F . instr insert t into q M . nextlist = merge ( M 1 . nextlist , L . nextlist , makelist ( nextinstr ) ) emit ( ‘goto-’ ) L → S L . nextlist = S . nextlist L → L 1 F S backpatch ( L 1 . nextlist , F . instr ) L . nextlist = S . nextlist \begin{array}{|ll|}
\hline
\text{产生式} & \text{语义规则} \\
\hline
S \rightarrow \text{switch} (E) H \{ M \, \text{default}:F \, L \} & S.\text{nextlist} = \text{merge}(M.\text{nextlist}, L.\text{nextlist}, \text{makelist}(\text{nextinstr})) \\
& \text{emit}(\text{`goto-'}) \\
& \text{backpatch}(H.\text{list}, \text{nextinstr}) \\
& \text{for t in } q: \\
& \quad \text{gen}(\text{`if'} \, E.\text{addr } \text{`==' } t.c \, \text{`goto' } t.d) \\
& \text{emit}(\text{`goto' } F.\text{instr}) \\
\hline
H \rightarrow \varepsilon & \text{set q as } \varnothing \\
& H.\text{list} = \text{makelist}(\text{nextinstr}) \\
& \text{emit}(\text{`goto-'}) \\
\hline
F \rightarrow \varepsilon & F.\text{instr} = \text{nextinstr} \\
\hline
M \rightarrow \text{case} \, C:F \, L & t.c = C.\text{val} \\
& t.d = F.\text{instr} \\
& \text{insert } t \, \text{into } q \\
& M.\text{nextlist} = \text{merge}(L.\text{nextlist}, \text{makelist}(\text{nextinstr})) \\
& \text{emit}(\text{`goto-'}) \\
\hline
M \rightarrow M_1 \, \text{case} \, C:F \, L & t.c = C.\text{val} \\
& t.d = F.\text{instr} \\
& \text{insert } t \, \text{into } q \\
& M.\text{nextlist} = \text{merge}(M_1.\text{nextlist}, L.\text{nextlist}, \text{makelist}(\text{nextinstr})) \\
& \text{emit}(\text{`goto-'}) \\
\hline
L \rightarrow S & L.\text{nextlist} = S.\text{nextlist} \\
\hline
L \rightarrow L_1 \, F \, S & \text{backpatch}(L_1.\text{nextlist}, F.\text{instr}) \\
& L.\text{nextlist} = S.\text{nextlist} \\
\hline
\end{array} 产生式 S → switch ( E ) H { M default : F L } H → ε F → ε M → case C : F L M → M 1 case C : F L L → S L → L 1 F S 语义规则 S . nextlist = merge ( M . nextlist , L . nextlist , makelist ( nextinstr )) emit ( ‘goto-’ ) backpatch ( H . list , nextinstr ) for t in q : gen ( ‘if’ E . addr ‘==’ t . c ‘goto’ t . d ) emit ( ‘goto’ F . instr ) set q as ∅ H . list = makelist ( nextinstr ) emit ( ‘goto-’ ) F . instr = nextinstr t . c = C . val t . d = F . instr insert t into q M . nextlist = merge ( L . nextlist , makelist ( nextinstr )) emit ( ‘goto-’ ) t . c = C . val t . d = F . instr insert t into q M . nextlist = merge ( M 1 . nextlist , L . nextlist , makelist ( nextinstr )) emit ( ‘goto-’ ) L . nextlist = S . nextlist backpatch ( L 1 . nextlist , F . instr ) L . nextlist = S . nextlist For 循环的翻译方案#
(来自 22 年往年题)
产生式 语义规则 S → for ( S 1 M 1 ; B ; M 2 S 2 ) N S 3 backpatch ( B . truelist , N . instr ) ; backpatch ( N . nextlist , M 1 . instr ) ; backpatch ( S 1 . nextlist , M 1 . instr ) ; backpatch ( S 2 . nextlist , M 1 . instr ) ; backpatch ( S 3 . nextlist , M 2 . instr ) ; emit ( “goto” M 2 . instr ) ; S . nextlist = B . falselist ; M → ε M . instr = nextinstr ; N → ε N . nextlist = makelist ( nextinstr ) ; emit ( “goto” _ _ _ _ ) ; N . instr = nextinstr ; \begin{array}{|ll|}
\hline
\text{产生式} & \text{语义规则} \\
\hline
S \to \text{for} \ (S_1 \ M_1 \ ; B ; \ M_2 \ S_2) \ N \ S_3 & \text{backpatch}(B.\text{truelist}, N.\text{instr}); \\
& \text{backpatch}(N.\text{nextlist}, M_1.\text{instr}); \\
& \text{backpatch}(S_1.\text{nextlist}, M_1.\text{instr}); \\
& \text{backpatch}(S_2.\text{nextlist}, M_1.\text{instr}); \\
& \text{backpatch}(S_3.\text{nextlist}, M_2.\text{instr}); \\
& \text{emit}(\text{“goto”} \ M_2.\text{instr}); \\
& S.\text{nextlist} = B.\text{falselist}; \\
\hline
M \to \varepsilon & M.\text{instr} = \text{nextinstr}; \\
\hline
N \to \varepsilon & N.\text{nextlist} = \text{makelist}(\text{nextinstr}); \\
& \text{emit}(\text{“goto”} \ \_\_\_\_); \\
& N.\text{instr} = \text{nextinstr}; \\
\hline
\end{array} 产生式 S → for ( S 1 M 1 ; B ; M 2 S 2 ) N S 3 M → ε N → ε 语义规则 backpatch ( B . truelist , N . instr ) ; backpatch ( N . nextlist , M 1 . instr ) ; backpatch ( S 1 . nextlist , M 1 . instr ) ; backpatch ( S 2 . nextlist , M 1 . instr ) ; backpatch ( S 3 . nextlist , M 2 . instr ) ; emit ( “goto” M 2 . instr ) ; S . nextlist = B . falselist ; M . instr = nextinstr ; N . nextlist = makelist ( nextinstr ) ; emit ( “goto” ____ ) ; N . instr = nextinstr ; 注意这里,B B B M 2 M_2 M 2 N N N S 2 S_2 S 2 goto \text{goto} goto