中间代码#
中间代码是介于源代码和目标代码之间的一种代码形式,它既不依赖于具体的编程语言,也不依赖于具体的目标机。
- 对不同的程序语言进行编译时,可以采用同一种形式的中间代码。
- 同一种形式的中间代码,可以转换成不同目标机的目标代码。
- 在中间代码上可以进行各种不依赖于目标机的优化,这些优化程序可以在不同的程序语言和不同的目标机的编译程序中重复使用。
编译器前端的逻辑结构:
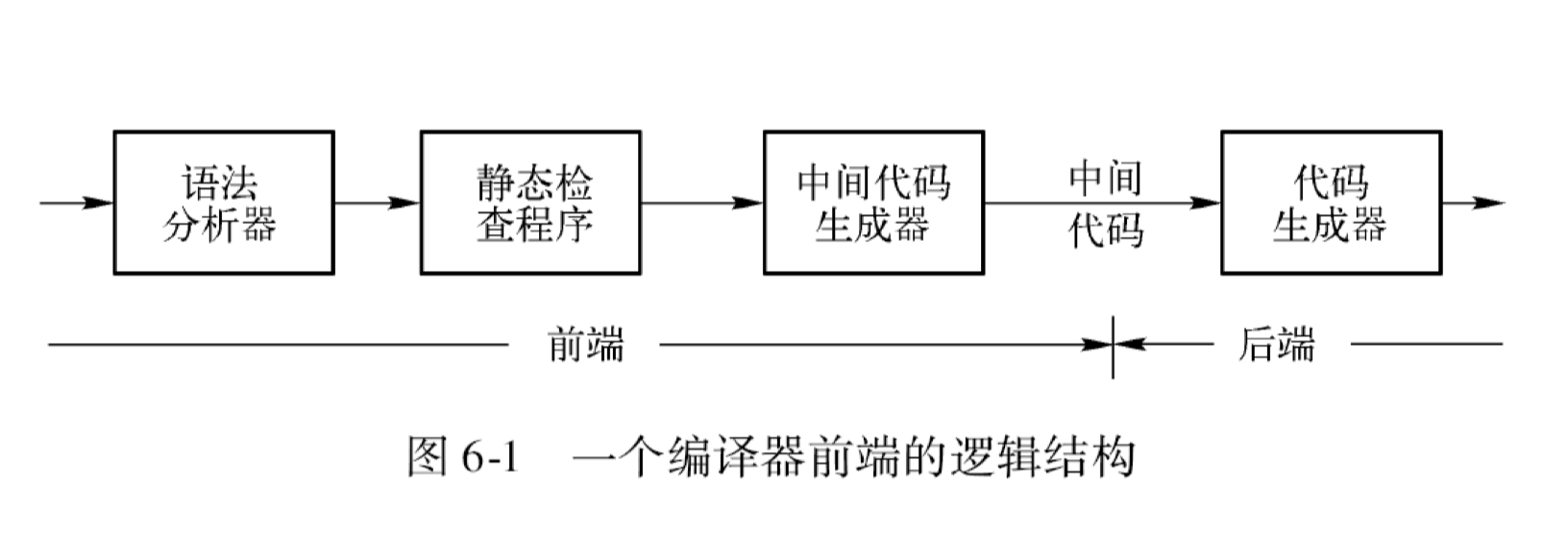
中间代码的表示形式#
- 抽象语法树(AST)
- DAG(Directed Acyclic Graph 有向无环图)
- 后缀式(也称逆波兰表示)
- 三地址代码
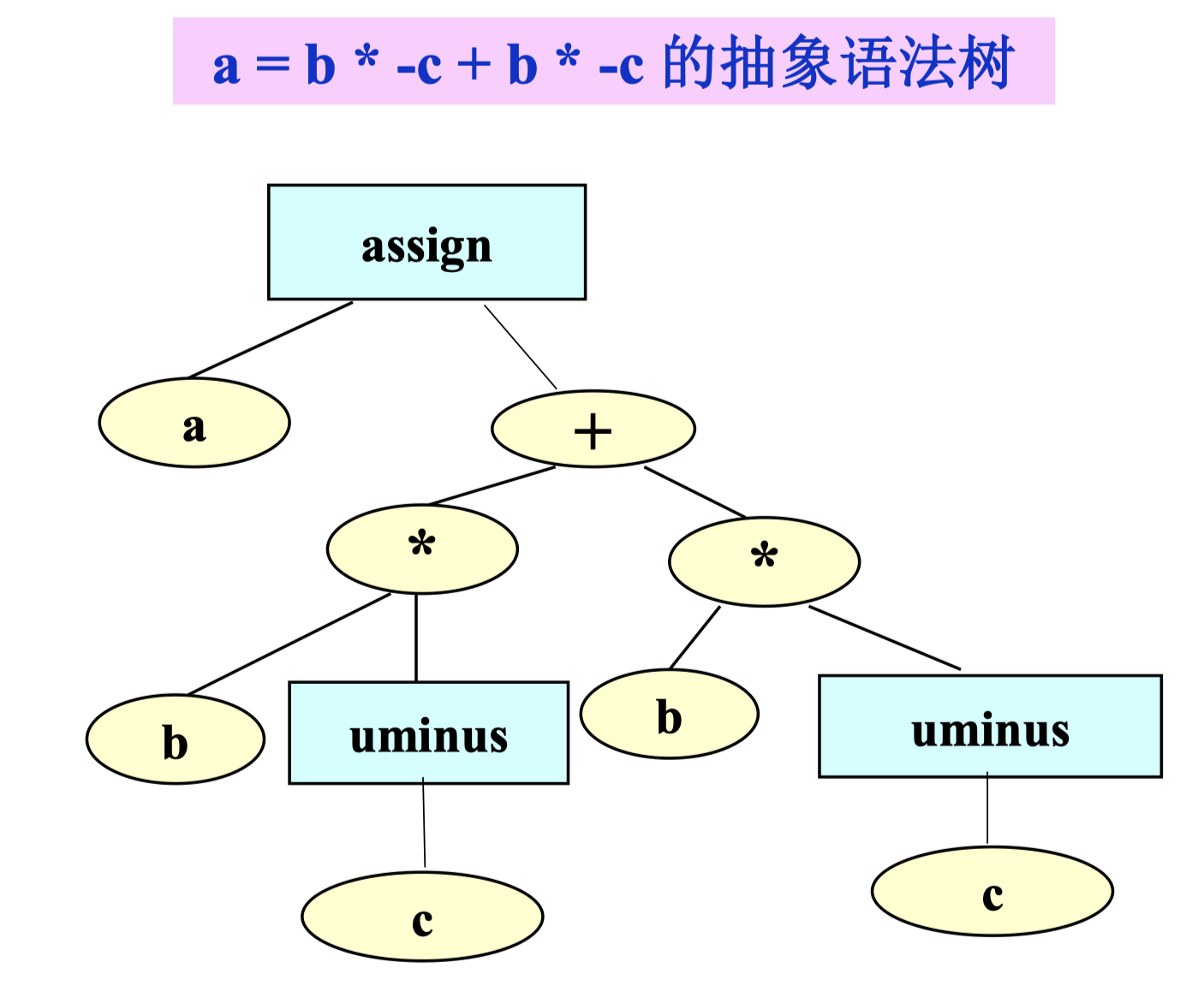
AST#
AST 抽象语法树的生成方式同前文章所述。
DAG#
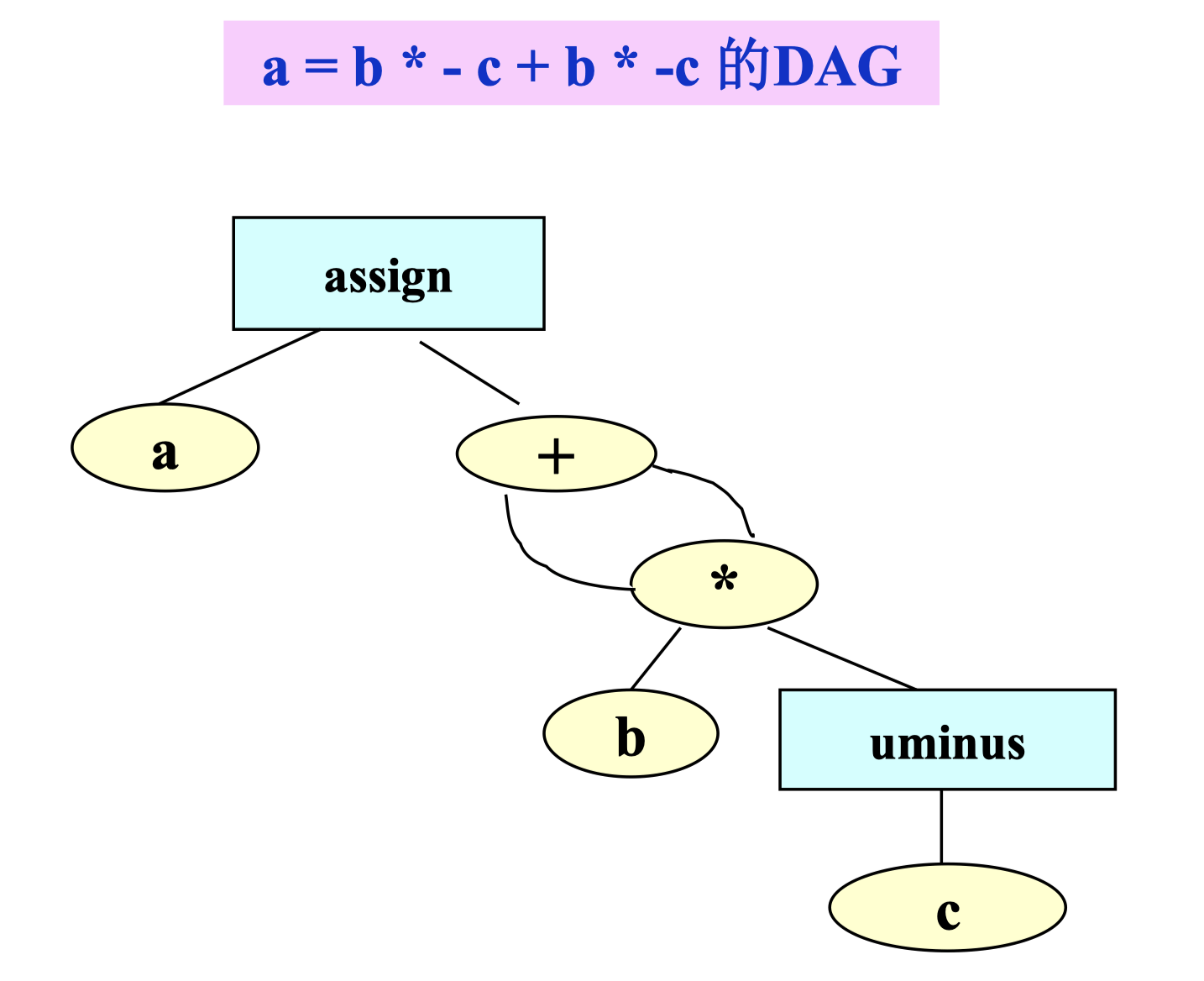
和 AST 的区别:尽可能的复用相同的节点。
这点在翻译上亦有体现:在产生表达式 DAG 的翻译方案中,每次调用 Leaf() 和 Node() 的构造函数时,要检查是否已存在相同结构的节点,如果存在,则返回找到的已有节点,否则构造新节点(但这在下表中不体现,所以看上去和 AST 没有区别)。
产生式E→E1+TE→TT→T1∗FT→FF→(E)F→idF→num语义动作{E.node=new Node (“+”,E1.node,T.node);}{E.node=T.node;}{T.node=new Node (“*”,T1.node,F.node);}{T.node=F.node;}{F.node=E.node;}{F.node=new Leaf(ID, id.name); }{F.node=new Leaf(NUM, num.val); }
由于这个检查的存在,DAG 生成效率降低了,但是运行效率提高了。
三地址代码#
基本形式:
x=y op z
类别:
-
一元运算:x=op y,op 是一元运算符,如一元减、逻辑非等。
-
复制指令:x=y
-
无条件跳转:goto L
-
条件跳转:if x goto L (x 为真时跳转)或 if False x goto L (x 为假时跳转)
-
条件转移:if x ROP y goto L,仅当 x ROP y 成立时跳转
ROP 是关系运算符,包括 <、≤、>、≥、==、!= 等
-
参数传递与函数调用:
- 首先使用 param x1、 param x2 ⋯ param xn 传递参数
- 然后使用 call p,n 调用函数,其中 p 是函数名,n 是参数个数
-
数组与地址操作
- 把数组元素 y[z] 的值赋给 x:x=y[z]
- 把 z 的值赋给数组元素 x[y]:x[y]=z
- 把 y 的地址赋给 x:x=&y
- 把 y 值为地址的存储空间的值赋给 x:x=∗y
- 把 y 值赋给 x 值为地址的存储空间:∗x=y
示例 1#
do i = i + 1; while (a[i] < v);
c符号标号#
L: t1 = i + 1
i = t1
t2 = i * 8
t3 = a[t2]
if t3 < v goto L
text位置号#
100: t1 = i + 1
101: i = t1
102: t2 = i * 8
103: t3 = a[t2]
104: if t3 < v goto 100
text三地址代码具体实现#
对于表达式
a=b∗−c+b∗−c
其三地址代码可以表示为如下几种方式。
四元式表示#
inst(0)(1)(2)(3)(4)(5)opuminus∗uminus∗+assignarg1cbcbt2t5arg2t1t3t4resultt1t2t3t4t5a
三元式表示#
inst(0)(1)(2)(3)(4)(5)opuminus∗uminus∗+assignarg1cbcb(1)aarg2(0)(2)(3)(4)
注:三元式中可以使用指向三元式语句的指针来表示操作数。
间接三元式表示#
address012345inst(0)(1)(2)(3)(4)(5)
inst(0)(1)(2)(3)(4)(5)opuminus∗uminus∗+assignarg1cbcb(1)aarg2(0)(2)(3)(4)
间接三元式:三元式表 + 间接码表。
间接码表是一张指示表,按运算的先后次序列出相关三元式们在三元式表中的位置。
这样,修改语句顺序的时候,只需要修改间接码表,而不需要修改三元式表,方便优化。
不同表示方法的对比#
- 四元式需要利用较多的临时单元,四元式之间的联系通过临时变量实现
- 中间代码优化处理时,四元式比三元式更为方便
- 间接三元式与四元式同样方便,两种实现方式需要的存储空间大体相同
静态单赋值(SSA)#
SSA(Static Single Assignment):每个变量在 SSA 形式中只赋值一次,每次赋值都对应一个不同的变量名。
转换前:
p = a + b
q = p - c
p = q * d
p = e - p
q = p + q
cpp转换后:
p1 = a + b
q1 = p1 - c
p2 = q1 * d
p3 = e - p2
q2 = p3 + q1
cppPhi 函数#
作用:在不同路径中对同一个变量赋值时,使用 ϕ 函数来合并不同的赋值。
示例:
if (flag) x = -1;
else x = 1;
y = x * a;
c转换前:
if(flag)x=−1;elsex=1;y=x∗a;
转换后:
if (flag)x1=−1;elsex2=1;x3=ϕ(x1,x2);y=x3∗a;
类似于 ICS 中学到的条件转移 cmov 指令。
类型和声明#
类型检查(Type Checking):利用一组规则来检查运算分量的类型和运算符的预期类型是否匹配。
语言类型#
-
类型化的语言:变量都被给定类型的语言。
特点:表达式、语句等语法构造的类型都是可以静态确定的。
例如,类型为 boolean 的变量 x 在程序每次运行时的值只能是布尔值,not(x) 总有意义。
-
非类型化的语言:不限制变量值范围的语言。
特点:一个运算可以作用到任意的运算对象,其结果可能是一个有意义的值,一个错误,一个异常或一个语言未加定义的结果。
类型表达式#
类型表达式 (Type Expression):用来表示源程序中变量、常量、表达式、语句等语言成分的类型。
种类:
- 基本类型:boolean, char, integer, float 等
- 类名
- 数组类型:array
- 记录(结构)类型:record
- 函数类型:s→t 从 s 到 t 的函数表示为 s→t
- 笛卡尔积:用 × 表示列表或元组(例如函数参数)
- 指针类型
- 类型表达式的变量
类型表达式的例子#
C 语言的类型:
struct {
int no;
char name[20];
}
c类型表达式为:
record((no×integer)×(name×array(20,char)))
类型等价 (Type Equivalence)#
类型等价:两个类型的值集合相等并且作用于其上的运算集合相等。
特点:具有对称性。
种类:
- 按名字等价:两个类型名字相同,或者被定义成等价的两个名字
- 按结构等价:两个类型的结构完全相同,但是名字不一定相同
按名字等价一定是按结构等价的。
类型兼容 (Type Compatibility)#
类型兼容:两个类型可以替换而不会引起类型错误。
注意,其是针对某种运算而言,而且类型相容 不具有对称性。
比如,在有的语言中,整型类型对实型值运算与实型类型相容。
即允许把整型的值赋给实型变量,但不允许把实型的值赋给整型变量。
声明语句#
文法:
D→T id ; D ∣ εT→B C ∣ record “{” D “}”B→int ∣ floatC→ε ∣ [num] C
含义:
D 生成一系列声明(Declaration)T 生成不同的类型(Type)B 生成基本类型 int/floatC 表示分量,生成 [num] 序列
注意 record 中用 D 嵌套表示各个字段的声明。
字段声明和变量声明的文法一致。
局部变量的存储布局#
- 变量的类型可以确定变量需要的内存(即类型的宽度)
- 可变大小的数据结构只需要考虑指针
- 函数的局部变量总是分配在连续的区间
- 给每个变量分配一个相对于这个区间开始处的相对地址,变量的类型信息保存在符号表中
计算 T 的类型和宽度的 SDT#
综合属性:type, width
全局变量 t 和 w 用于将类型和宽度信息从 B 传递到 C→ε
相当于 C 的继承属性,因为总是通过拷贝来传递,所以在 SDT 中只赋值一次。
也可以把 t 和 w 替换为 C.type 和 C.width(继承属性)
产生式T→BT→ CB→intB→floatC→εC→[num]C1动作{t=B.type;w=B.width;}{T.type=C.type;T.width=C.width}{B.type=integer;B.width=4;}{B.type=float;B.width=8;}{C.type=t;C.width=w;}{C.type=array(num.value,C1.type);}{C.width=num.value×C1.width;}
例子:
