机器学习介绍与线性模型
机器学习
机器学习,指通过算法的设计与分析,使得:
- 模型的 表现 得到提升
- 在某些 任务 上
- 基于 经验
机器学习的任务
- 有监督学习:这种方式需要提前给模型提供 “正确答案”,让模型在学习过程中有明确的参照。比如:
- 分类问题:判断输入数据属于哪个类别,例如判断一封邮件是不是垃圾邮件。
- 回归问题:预测一个连续值,例如预测房屋的价格。
- 无监督学习:模型在没有 “正确答案” 的情况下自我学习,它会尝试理解数据的结构。
- 聚类:将数据分组,组内相似度高,组间相似度低,例如将顾客分为不同的群体。
- 密度估计:估计数据生成的概率分布,例如在数据中找出异常点。
- 降维:减少数据的复杂性,同时保留重要特征,例如用于数据可视化。
半监督学习:结合了有监督和无监督学习,使用大量未标记数据和少量标记数据进行学习。
弱监督学习:标记数据不完全、不确切或不可靠,但仍旨在通过这些不完美的标记来进行学习。
强化学习:模型通过与环境的交互来学习,它试图找出在给定情况下的最佳动作,以最大化所获得的奖励。
机器学习的经验
训练数据 vs 测试数据
一个好的机器学习算法:
- 不会过拟合(overfit)
- 训练数据可以泛化(generalize)到测试数据
机器学习的表现
表现的衡量方法:从一个随机测试数据 ,衡量真实标签 和预测 之间的接近程度
二元分类(Binary Classification)
二元分类是一个简单的分类问题,只有两个类别的结果。
损失函数为 0/1 损失,即如果预测正确,损失为 0;预测错误,损失为 1。
二元分类的 0/1 损失函数
其中, 是指示函数,当 (预测值)不等于 (真实值)时,结果为 1,表示有损失;否则结果为 0,表示没有损失。
回归(Regression)
在回归任务中,我们预测 连续的输出值。
损失函数为 平方损失,即预测值与真实值之差的平方。
回归的平方损失函数
这里 表示预测值 与实际值 之间差的平方。这个值越小,表示预测越准确。
密度估计(Density Estimation)
密度估计是 估计输入数据概率分布 的任务。
密度估计属于 无监督学习,它的目标是估计一个变量的概率分布。这不需要标签数据。
损失函数为 负对数似然损失,这里衡量的是模型对真实分布的拟合程度。
密度估计的负对数似然损失函数
其中, 是模型预测的数据点 的概率(也即模型认为数据点 出现的可能性)。负对数似然损失函数衡量的是模型对数据生成概率的估计与实际分布的拟合程度。这个值越小,表示模型的估计越接近真实分布。
机器学习的理想目标
机器学习的目标是构建适用于任何测试数据点 的预测规则 ,它可以最小化损失函数的期望值:
其中, 表示对联合分布 的期望, 是预测误差。
但是,我们并不知道数据的真实分布情况,无法直接求解这个式子。
为此,我们通过使用引入训练数据(可以看做是经验)来近似这个期望。
训练数据可以表示为 ,它提供了关于 分布的一些信息。
如此一来,我们的目标就变成了
线性模型
线性模型:线性模型就是要学习特征 的一种线性组合来进行预测,进行运算 ,其中 是 的权重, 是偏置, 是预测值。
我们希望通过学习得到最优的 和 ,使得预测值 与真实值(ground truth) 的误差最小。
其中, 具有 个特征,,其每个分量都代表一个特征,,是 各个特征的线性组合。
线性回归:给定数据 , 用一个线性模型估计最接近真实 的连续标量: , 也就是要
其中, 是要学习的模型参数。
也就是要:
由于我们不能无限地获得数据,所以我们只能通过有限的数据来估计这个期望,也就是:
这也被称为 Empirical mean(经验均值)。
其中, 是数据的数量, 是第 个数据的全部特征, 是第 个数据的真实值, 是第 个数据的预测值。
根据大数定理,当数据量足够大时,经验均值会趋近于期望,也就是:
我们可以通过最小二乘法来获取最优的 和 。
我们选择以线性代数来表示这个问题,也就是 Least Squares Estimator(最小二乘估计):
我们将之转为矩阵形式:
注意这一步的 的每一行代表一个数据 ,每一行除了最后一列,都是 的特征,最后一列是 ,这是一个小的 trick,因为这样做的话,我们就可以把 合并到 中,也就是:
我们可以得到:
其中, 是最优的 ,也就是我们要求的结果。
简化这个式子,去掉和优化无关的 ,我们可以得到:
这里第三个等号利用了中间两项互为转置且均为标量的性质合并了他们。第四个等号则应用了矩阵求导的性质。
如果 可逆,那自然可以根据上式求出 的解:
但是,很多情况下, 并不可逆,比如 时,我们可以证明它一定不可逆。而且即使 可逆( 此时要求样本个数 要大于等于待估参数量 ,包含截距项,同时 满秩 / 可逆,我们称此式有闭式解 ),当它的维度很大时,计算也是很昂贵的。
所以,我们可以通过梯度下降法来求解最优的 。
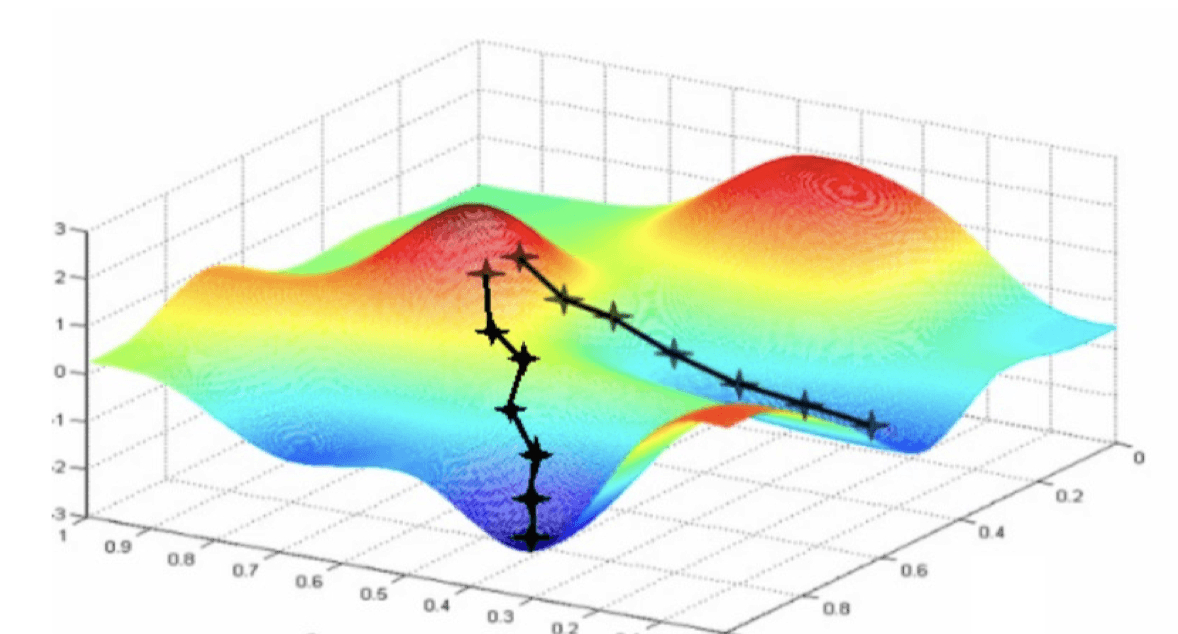
gd
梯度下降法的思想是:从随机选取的 开始,每次沿着梯度的反方向走一步(走的多长由学习率 Learning Rate 决定),直到收敛。只要这个损失函数是凸函数,我们总能优化到最优点。
贝叶斯统计
第一行的含义是,我们要最大化数据的似然函数和参数的先验概率的乘积。
- 似然函数表示数据()在给定参数 的情况下出现的概率
- 先验概率表示我们在看到数据之前对参数的信念。
最大化这个乘积等价于最大化它们的对数,因为对数是单调递增的函数。
第二行的第一个项代表的含义是,在给定参数 和方差 的情况下,数据出现的概率。
在统计模型中:
- 通常代表模型的系数
- 代表模型中的噪声或误差的方差。即使我们有了 ,我们还需要知道数据中的变异性(或不确定性)有多大,这就是为什么 是重要的。
在某些模型,比如线性回归中,我们假设数据 是由自变量 的线性组合(由 确定)加上一些随机噪声(由 描述)生成的。这个噪声代表了除了 影响 之外的其它因素。所以, 帮助我们了解除了主要效应(由 描述)之外,数据中还有多少随机波动。
我们采取高斯先验,也即假设参数遵循高斯分布(也称为正态分布)。那么也就有 。
这表示:
- 参数 是一个 N 维向量,其中 N 是特征的数量
- 其遵循均值为 0,方差为 的多元高斯分布
- 是指协方差矩阵为 的对角矩阵,这代表 的每个元素都是相互独立的,且每个元素的方差都是 。
- 也就是说,各个维度独立同分布(iid)。
的概率密度分布函数按照矩阵表示,则是:
可以比较一维版本来理解~
其中的 是协方差矩阵的行列式,它的作用是保证概率密度函数的总面积为 1。而当它为对角矩阵时,还能额外保证各个维度彼此独立。
所以,我们有 。
这不包括归一化常数。 表示成比例,意味着这是未归一化的概率密度,它的形状随着 的变化而变化,但是总面积(概率总和)是固定的。 是 的二次项,表示参数向量的长度的平方。
关于这一部分,可以阅读 钱默吟/多元高斯分布完全解析,讲的很详细。
这个式子的一个直观理解,就是假设 是一个二维的,那么我们可以可视化这个分布:
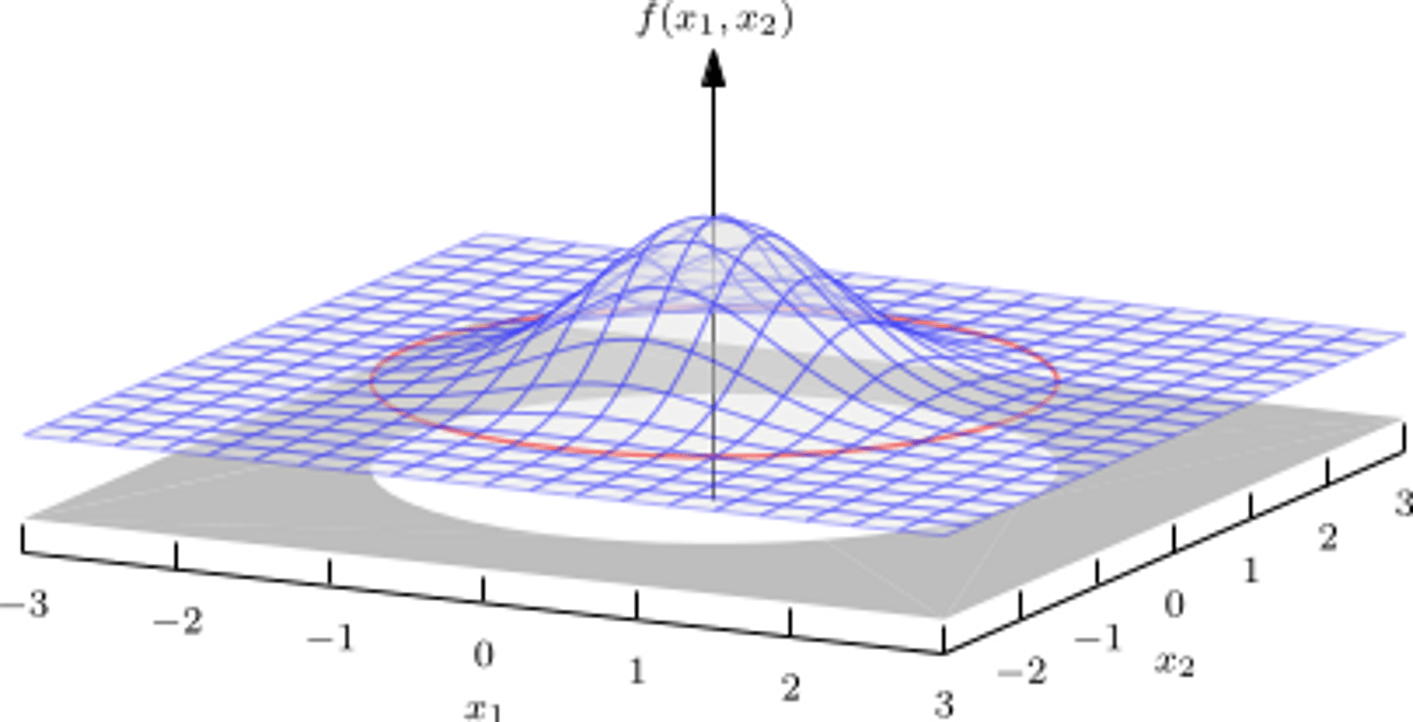
gaussian_distribution
那么在这个图中,任意一个点都对应一个高斯分布,而 就是这个点的概率密度。我们可以看到,这个分布是关于原点对称的,这也是 中的 的作用,这代表了我们对于变量的顺序是没有偏好的。
带入进行复杂的数学推导 [^1] 后,我们就可以得到:
为什么刚才是 ,现在又变成了 ?简单说明就是,刚才我们要最大化从已知的 中得到数据真实分布的概率,这就等价于最小化使用我们的模型,从 中得到的数据的误差(也即最大似然估计)。
而 是一个超参数,它的作用是控制我们对于参数的偏好,也就是我们对于模型的复杂度的偏好。在后续的学习中,我们会知道 其实是一个正则项,它的作用是防止过拟合。
当我们对于 的先验假设不一样时,这个惩罚项(正则项)也会不一样。但大致原理不变,于是我们对这个形式加以推广,得到了类似如下的公式:
其中, 是我们的损失函数, 是惩罚项。
对于惩罚项,我们一般有两个选择:
- L1 正则(1 - 范数):,见于 选择拉普拉斯分布作为先验分布
- L2 正则(2 - 范数):,见于 选择高斯分布作为先验分布
这两个惩罚项的解,具有如下特征:
- L1 套索回归的正则化项:,这是一个 L1 范数,它对所有系数施加相同的惩罚,这会导致一些系数直接为零,从而产生一个 稀疏解。非零 更少。
- L2 岭回归的正则化项:,这是一个 L2 范数,它对大的系数施加更大的惩罚,导致系数平滑地趋近于零。有些 更小。
简而言之:岭回归无法剔除变量,套索回归的优良性质是能产生稀疏性,可以将一些不重要的回归系数缩减为 0,达到剔除变量的目的。 [^2]
可以这么记忆:对于较小的数值,考虑两个惩罚项的导数 / 梯度:
- 对于 L1,惩罚项导数是一个常数,所以它会不区分大数值和小数值,因而小数值会更容易在这个梯度下降到 0,导致稀疏解
- 对于 L2,惩罚项导数是一个一次项,所以它会区分大数值和小数值,对于大数值的下降更大,而对于小数值的下降很小,甚至趋于 0,所以他只是容易让参数变小,但不太会让它们达到 0。
最终,我们得到广义的线性模型,我们可以考虑任意一种单调可微的函数 :
其中, 是激活函数,它的作用是将线性模型的输出转换为我们想要的输出,也即将线性模型的输出转换为一个非线性的预测值。比如,当 是恒等函数时,我们就得到了线性回归;当 是 sigmoid 函数时,我们就得到了逻辑回归。
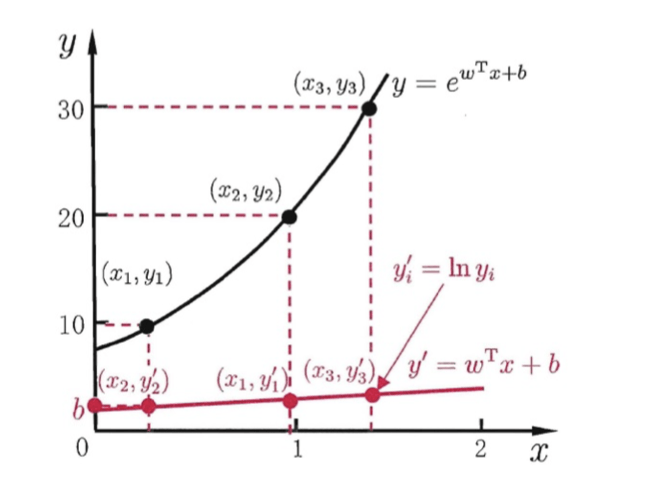
nonlinear
在这个图中, 就是 函数,而对应的 就是 指数函数。通过这个变换,我们将一个线性的 变换得到了非线性的 。
Credit
关于最大化高斯分布的后验概率等价于最小化二阶范数的具体推导,还有一个由 GPT4 生成的推导过程:
在高斯分布下,假设权重 遵循均值为 0,方差为 的正态分布,即 。那么权重的概率密度函数(PDF)为:
取对数得到:
因为第一项 是常数,对于优化问题,我们只考虑影响模型参数 的项,所以可以忽略它。因此,我们只关注第二项:
在机器学习中,我们通常使用代价函数(或损失函数)来训练模型。假设我们的代价函数为 ,为了使 接近于高斯分布,我们可以在代价函数中增加对数先验 ,即:
其中 是正则化参数。将 代入上式得到:
我们可以看到这里的 起到了正则化系数的作用。这个正则化项是 的平方,即 正则项。通常我们将 正则化系数表示为 ,所以代价函数可以写为:
这显示了在高斯分布下 的效果等价于在代价函数中增加 正则项。这种正则化有时也被称为权重衰减,它鼓励模型学习更小的权重,从而可以提高模型的泛化能力,防止过拟合。